
第一章 基本概念
1.1什么是Internet?
1.各层次的功能
物理层:在物理媒体上为数据端设备透明地传递原始比特流。传输单位是比特。
数据链路层:功能可以概括为成帧、差错控制、流量控制和传输管理等。传输单位是帧。
网络层:将网络层的协议数据单元(分组)从源端传到目的端,为分组交换网上的不同主机提供通信服务。对分组进行路由选择,并实现流量控制、阻塞控制、差错控制和国际互联等功能。传输单位是数据报。 常用协议:
- ARP:根据IP地址获取对应的MAC地址,通过一问一答实现交互,问是通过广播形式实现,答是通过单播形式。
- ICMP:在ip网络设备之间发送控制报文,传递差错、控制、查询等信息。可根据ICMP查看要发送的数据是否成功送达。若未成功送达的话,可查看发送失败的原因。
- DHCP:给主机动态的分配ip地址,无需人为参与。
- IP协议:寻址和路由。
传输层:为端到端提供可靠的传输服务,为端到端连接提供流量控制、差错控制、服务质量、数据传输管理等服务。传输单位是报文段(TCP)或者用户数据报(UDP)。
- TCP:可靠的、面向连接、传输效率低。(需要确认对接)
- UDP:不可靠的、无连接、传输效率高。(不需要确认对接)
会话层:负责管理主机间的通话进程,包括建立、管理以及终止进程间的通话。
表示层:主要处理在两个通信系统中交换信息的表示方法。
应用层:为特定类型的网络应用提供访问OSI参考模型环境的手段。传输单位是报文。
- DNS:将域名转换为ip地址。
- FTP:用于ftp客户端和ftp服务器之间进行文本、文件传输。
- SMTP:提供可靠且有效的电子邮件传输的协议。
- HTTP:规定了浏览器和服务器之间请求和响应的格式与规则。
- HTTPS:在Http和Tcp之间加入SSL/TLS协议,对传输信息进行加密。
2.网络
从具体构成角度
节点
- 主机及其上运行的应用程序。
- 路由器、交换机等网络交换设备。
边:通信链路
- 接入网络链路:主机连接到互联网的链路。
- 主干链路:路由器间的链路。
协议
- 协议定义了在俩个或多个通信实体之间交换的报文格式和次序,以及在报文传输和/或接受或其他事情方面所采取的动作。
数以亿计的、互联网计算设备:
- 主机=端系统。
- 运行网络应用程序。
通信链路
- 光纤、同轴电缆、无线电、卫星。
- 传输速率=宽带(bps)。
分组交换设备:转发分组(packets)
- 路由器和交换机。
从服务角度
使用通信设施进行通信的分布式应用
- Web、VoIP、email、分布式游戏、电子商务、社交网路……
通信基础设施为apps提供编程接口(通信服务)
将发送和接收数据的apps与互联网连接起来。
为app应用提供服务选择、类似于邮政服务
- 无连接不可靠服务(UDP)。
- 面向连接的可靠服务(TCP)。
1.2网络边缘
网络结构
网络边缘(edge)
- 主机。
- 应用程序(客户端和服务器)。
网络核心
- 互连着的路由器。
- 网络和网络。
接入网、物理媒体(access)
- 有限或者无线通信链路。
端系统(主机):
- 运行应用程序。
- 如Web、email。
- 在“网络的边缘”。
客户/服务器模式(C/S)
- 客户端向服务器请求,接受服务。
- 如Web浏览器/服务器:email客户端/服务器。
对等(peer-peer)模式(P2P)
- 很少(甚至没有)专门的服务器。
- 如Gnutella,kaZaA,Emule。
采用网络设施的面向连接服务(TCP)
目标:在端系统之间传输数据。
握手:在数据传输之前准备
- 人类协议中:你好、你好。
- 俩个通信主机之间为连接建立状态。
TCP—传输控制协议(Transmission Control Protocol)
- Internet上面向连接的服务。
TCP服务
可靠地,按顺序地传送数据
- 会确认是否接受和重新传送。
流量控制
- 发送方不会淹没接收方。
拥塞控制
- 当网络拥塞时,发送方降低发送速率。
采用基础设施的无连接服务(DUP)
目标:在端系统之间传输数据
- 无连接。
UDP—用户数据报协议(User Datagram Protocol)
- 无连接。
- 不可靠数据传输。
- 无流量控制。
- 无拥塞控制。
使用TCP的应用
- HTTP(Web)、FTP(文件传送)、Telnet(远程登录)、SMTP(email)。
使用UDP的应用:
- 流媒体、远程会议、DNS、Internet电话。
1.3网络核心
网络核心:路由器的网状网络
基本问题:数据怎样通过网络进行传输的?
电路交换:为每个呼叫预留一条专有电路:如电话网。
分组交换
- 将要传送的数据分成一个个单位:分组。
- 将分组从一个路由器传到相邻路由器(hop),一段段最终从源端传到目标端。
- 每段:采用链路的最大传输能力(带宽)。
电路交换
端到端的资源被分配给从源端到目标端的呼叫“call”:
电路交换例子

为呼叫预留端-端资源
- 链路带宽、交换能力
- 专用资源:不共享
- 保证性能
- 要求建立呼叫连接
网络资源(如带宽)被分成片
为呼叫分配片
如果某个呼叫没有数据,则其资源片处于空闲状态(不共享)
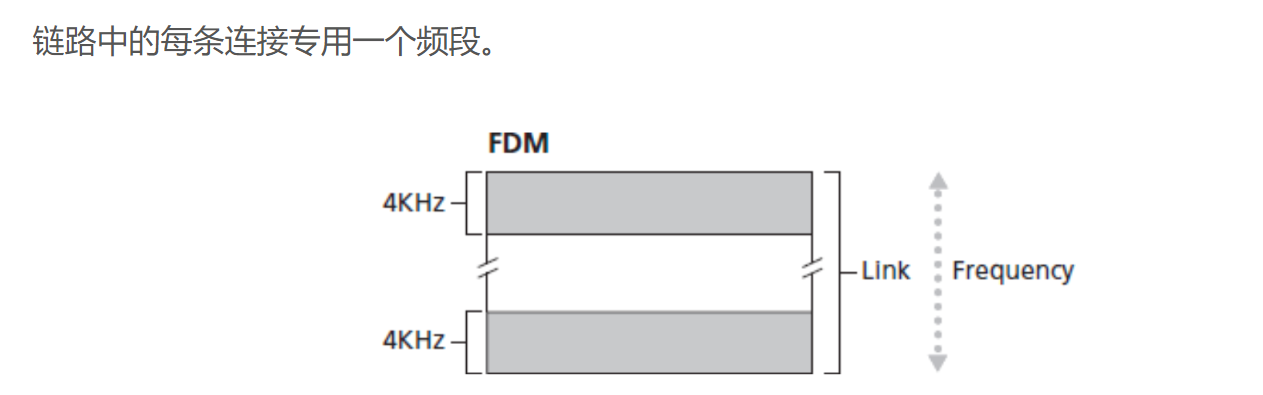
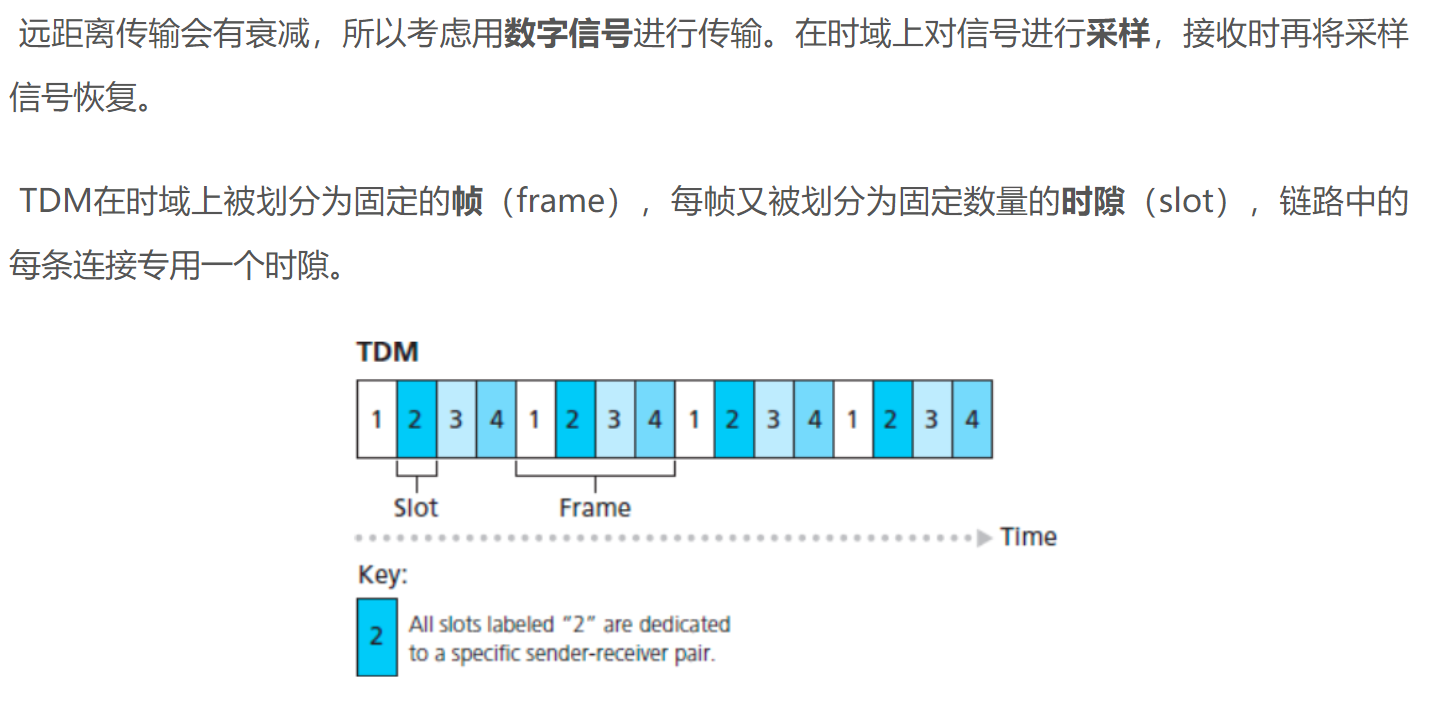
将带宽分成片
- 频分(FDM)
- 时分(TDM)
- 波分
- FDM和TDM

- 频分(FDM)
缺点:
- 连接建立时间长。
- 计算机之间的通信有突发性,如果使用线路交换,则浪费的片较多。即使这个呼叫没有数据传递,其所占据的片也不能够被别的呼叫使用。
- 可靠性不高。
分组交换
以分组为单位存储-转发方式

- 网络带宽资源不再分分为一个个片,传输时使用全部宽带。
- 主机之间的传输的数据被分为一个个分组。
资源共享,按需使用
存储-转发:分组每次移动一跳(hop)
- 在转发之前,节点必须收到整个分组(packet)。

- 延迟比线路交换要大。
- 排队时间。
- 在转发之前,节点必须收到整个分组(packet)。
排队和延迟
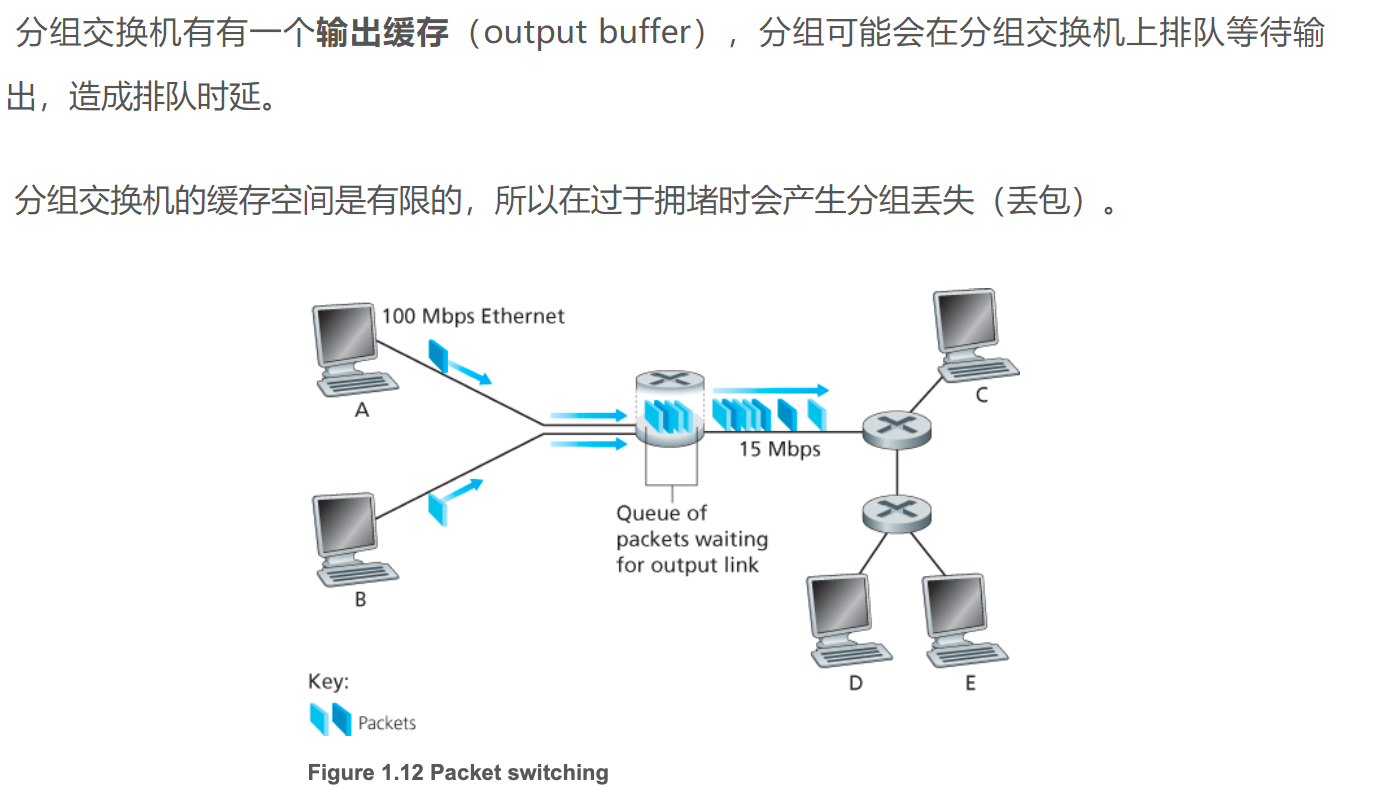
如果到达率>链路的输出速率
- 分组将会排队,等待传输。
- 如果路由器的缓存用完了,分组将会被抛弃。
转发表和路由选择协议
- 路由:分组中包括IP地址;
- 转发:路由器中将目的地址映射为输出链路。路由算法。
网络结构
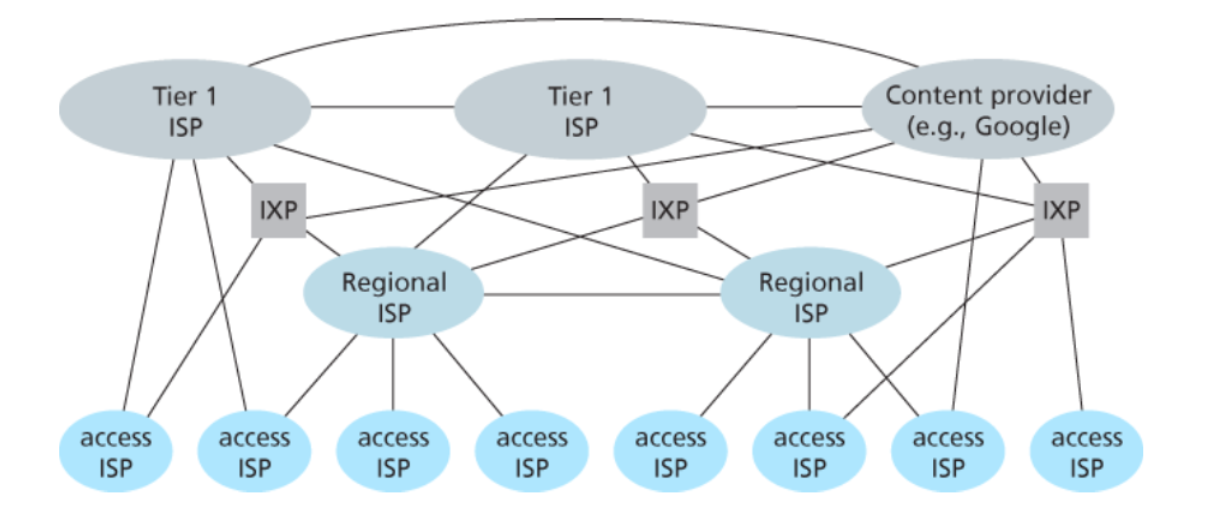
网络结构是网中网,具有层次结构
- ISP:ISP分为许多层级,比如第一层ISP(tier-1 ISP)、区域ISP(regional ISP)、接入ISP(access ISP)。端系统通过接入ISP与因特网相连,全球的ISP通过各层级相连,形成了互联网的互联。
- 因特网交换点(Internet Exchange Point、IXP):由第三方公司创建,IXP是一个汇合点,多个ISP在此处对等。
1.4协议(protocol)
协议定义了在俩个或多个通信实体之间交换的报文格式和次序,以及报文发送和/或接受一条报文或其他时间所采取的动作。
协议的三大要素
- 语法(Syntax):每一段内容符合一定规则的格式,比如一个报文前8位是原地址,后八位是目的地址(只是举例)之类。
- 语义(Semantics):每一段内容需要代表某种意义,比如原地址部分的二进制到底是指哪个地址。
- 同步(Timing):通信的过程,即每一段任务的执行顺序。
- 协议例子:
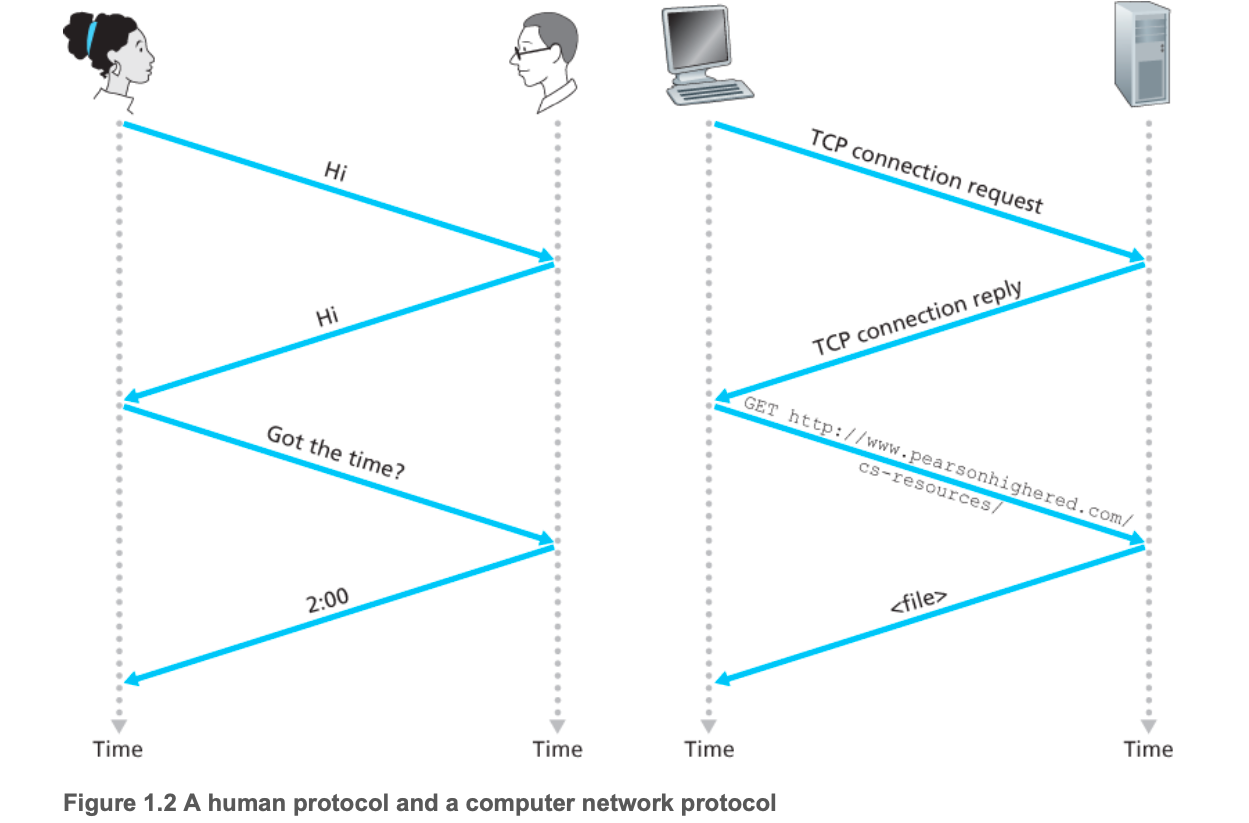
1.5协议层次(Protocol Layer)及其服务模型
1.五层因特网协议栈
因特网协议栈由5个层次组成:物理层、链路层、网络层、传输层和应用层。因特网协议栈是一个理想模型。
下层为上层提供服务。越下面的层次,越靠近硬件;越上面的层次,越靠近用户。
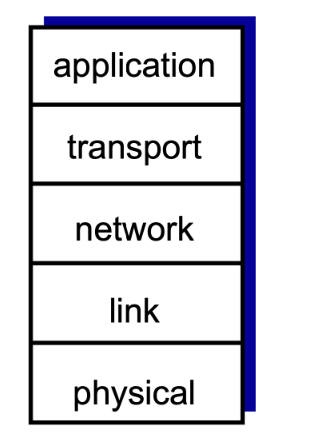
层次 功能 应用层(Application Layer) 支持网络应用,应用协议仅仅是网络应用的一个组成部分,运行在不同主机上的进程则使用应用层协议进行通信。 传输层(Transport Layer) 负责为信号源和信号宿主提供应用程序进程间的数据传输服务,这一层上主要定义了俩个传输协议,传输控制协议即TCP和用户数据报协议UDP。 网络层(Network Layer) 负责将数据报独立地从信号源发送到信号宿主,主要解决路由选择,拥塞控制和网络互联等问题。 链路层(Link Layer) 负责将IP数据报封装成合适在物理网路上传输的帧格式并传输,或将从物理网络接受到的帧解封,取出IP数据交给网络层。 物理层(Physical Layer) 负责将比特流在节点间传输,即负责物理传输。该层的协议既与链路有关也与传输介质有关。
2.OSI模型
- OSI模型由国际标准化组织(ISO)指定,实际并没有应用,只有理论。
- OSI模型由7层组成:应用层、表示层、会话层、传输层、网络层、数据链路层、物理层。
3.封装(Encapsulation)
在发送端:
- 应用层:将应用层报文(application-layer message)M传送给传输层;
- 传输层:接收报文M,附上传输层首部信息Ht(包括差错检测位信息等),构成 传输层报文段(transport-layer segment),将其传递给网络层;
- 网络层:
- 接收传输层报文段,附上网络层首部信息Hn(包括源和目的地址等),构成 网络层数据段(network-layer datagram),将其传递给网络层;
- 链路层:接收网络层数据段,附上链路层首部信息Hl,构成 链路层帧(link-layer frame),将其传递给物理层;
- 物理层:负责比特流物理传输。
在接收端以反方向重构报文段。
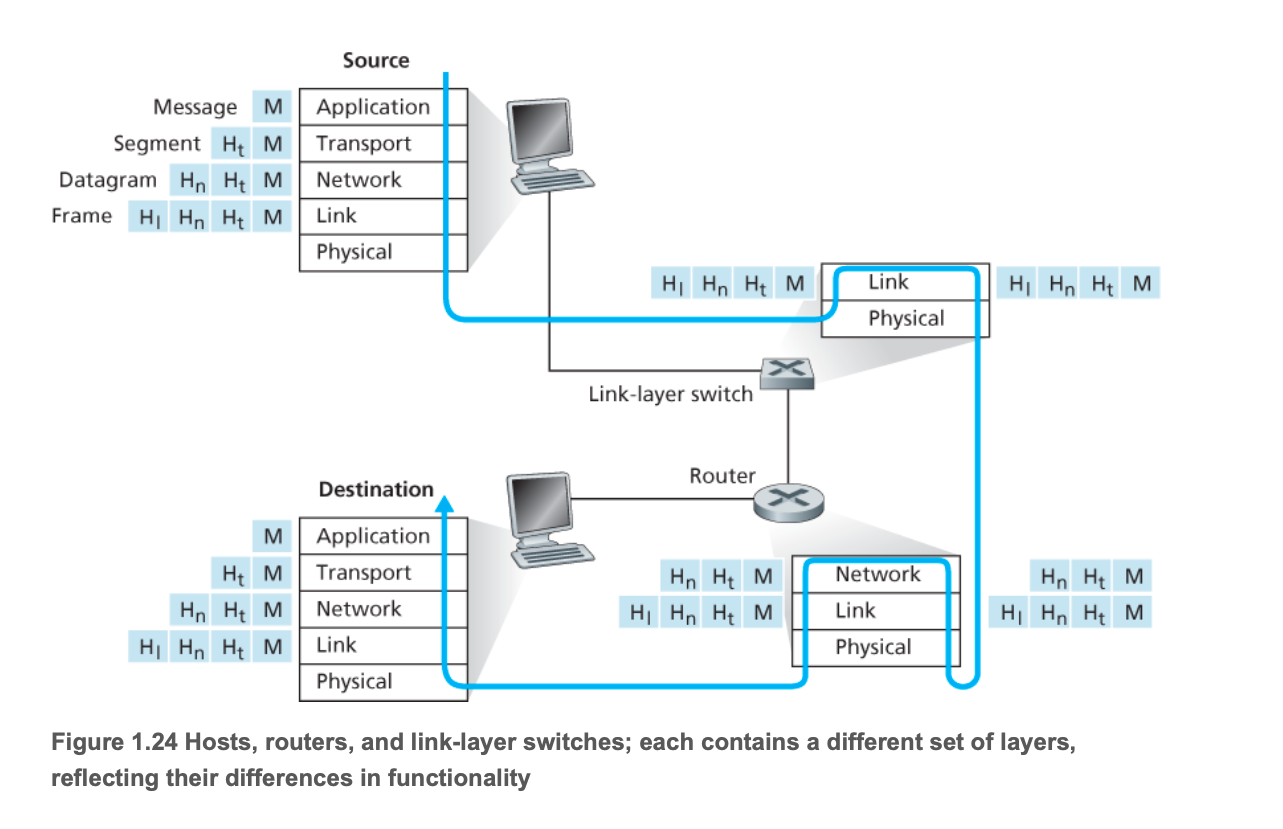
1.6物理层
- 概述:在俩个物理媒体间进行比特流传输,上层都是逻辑链接,只有物理层是实际的物理连接。
1. 物理层的基本目标
- 保证发送信号“0”和“1”的正确性以及发送和接受的一致性。
- 比特流传输的模式、速度、持续时间和信号失真。
- 接口设计:引脚数目、功能等等。
- 信号传输的程序:如何安排传输过程和事件次序。
2. 物理层的基本特征
- 机械特性:指明接口所用接线器的形状和尺寸,引线数目和排列、固定和锁定装置等。
- 电器特性:指明传输模式、电压范围、编码、阻抗匹配、传输速率以及传输距离等等。
- 功能特性:指明个物理线路的功能,比如某条线上出现的某一电平的电压表示何种意义,物理接口信号线按功能分为四类:数据线、控制线、定时线、地线;
- 规程特性:指明各物理线路工作规程和时序关系,比如对于不同功能的各种可能事件的出现顺序,信号传输的模式:单工(仅单向通行)、半双工(双方通,但一个时刻仅一方通)、全双工(双方随时通)。
1.7基本通信原理
基本概念
- 数据(data):对于客观事实描述的物理符号,包括数字、文本、语言、图像等等。
- 信息(information):数据的集合。
- 信号(signal):数据传输中的表现形式,比如模拟信号、数字信号。
- 信道(channel):往固定方向传输信息的媒介。
模拟传输VS数字传输
传输方式 优点 缺点 模拟 对信号有高利用率 不抗噪 数字 信号不易失真 需要更宽的带宽
信道特性
码元(Symbol):承载信息量的基本信号单位。
- 码元和比特位数关系
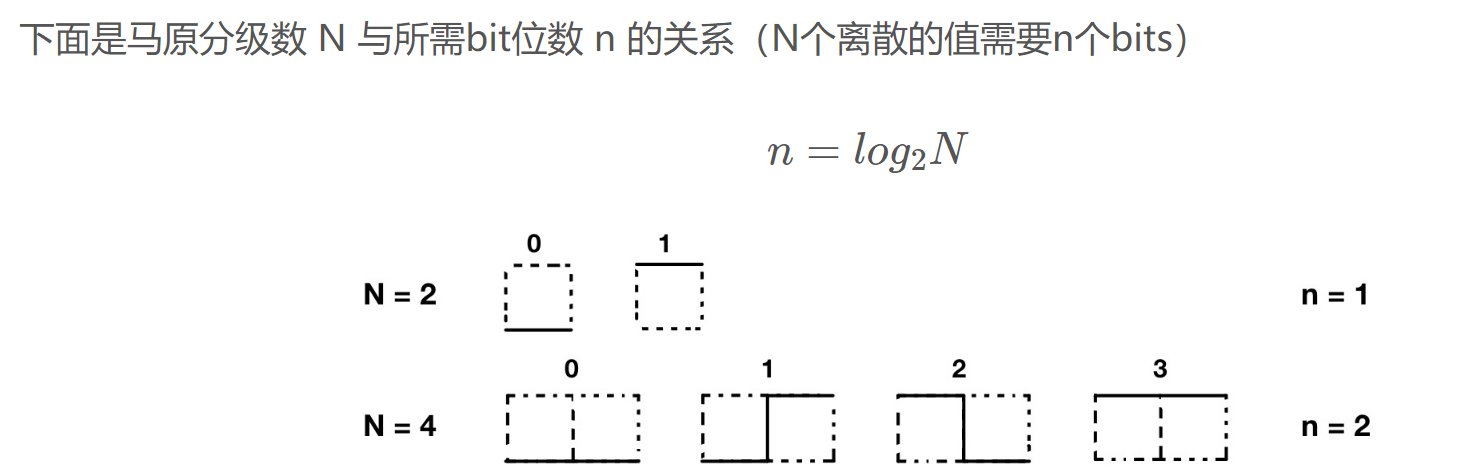
- 码元和比特位数关系
波特率(Baud rate):传输码元的速率。
比特率(bit rate):传输比特的速率。
- 波特率和比特率的关系

- 波特率和比特率的关系
信道容量(Channel capacity):在一个信道中能够可靠地传送信息时可达速率的最小上界,单位bps。
频带宽度(Frequency bandwidth):信道允许的信号频率范围,单位Hz。
传输延迟(Transmission delay):包括发送到接受的处理事件、电信号的响应时间、中间介质的传输时间。
奈奎斯特定理(Nyquist’s Law)
- 对于理想的低通信号,在一个频带宽度为 W 的信道,其码元的最大传输速率 = 2W Baud
- 对于理想的带通信号,在一个频带宽度为 W 的信道,其码元的最大传输速率 = W Baud
香农定理(Shannon’s Formula)
信道的信息传输速率C(单位:bps)
W - 带宽,单位 Hz
S - 信道的平均信号功率
N - 信道的高斯噪声功率
S/N - 信号功率与噪声功率之比(也可以叫信噪比)
一般情况下,信噪比不用 S/N表示,而是 10log10S/N10log10S/N ,单位为dB。
模拟/数字信号传输
- 模拟信道只能传输模拟信号,数字信道只能传输数字信号。
调制解调器

编码解码器

调制(Modulation):数字信号到模拟信号
- 从数字信号到模拟信号大调制主要有三种方法:

- 从数字信号到模拟信号大调制主要有三种方法:
脉码调制(Pulse Code Modulation, PCM)
模拟信号到数字信号:
脉码调制步骤:
- 采样(Sampling system):采样频率是信号频率的两倍,则可不失真地恢复原始信号。
- 量化(Quantify):取整采样信号。
- 编码(Coding):量化后的信号编码成二进制。

数字信号编码:
数字信号到数字信号:
不归零编码:
主要介绍俩种不归零编码
Non-Return-To-Zero Level (NRZ-L) Coding:高电平表示“1”,低电平表示“0”。

NRZ-L的优点:简单好实现
NRZ-L的缺点:
- 难以分清二进制一位的开始和结束,所以必须要带同步时钟(外同步)来同步。可以把上图的虚线当作是同步时钟,当把虚线去掉是,相同电平的信号就不好判断开始和结束了。
- 在传输全“1”或全“0”信号时,此时传输的只有直流分量(傅立叶分不出正弦或余弦分量),这样线路上会有比较大的噪声。
反向不归零编码(NRZ-I): 遇“1”反向。只能解决NRZ-L的部分问题(全“1”问题,不再是直流)

外同步(External synchronization)
给系统一个同步时钟信号,设置一个周期的宽度。
外同步有诸多不便,于是有了自同步的曼切斯特编码。
曼切斯特编码(Manchester encoding): 每个编码由两段组成,“1”:先高后低;“0”:先低后高(可以反过来定义):

曼切斯特编码的优点(解决了不归零编码的问题):
- 自同步,不需要同步时钟;
- 直流分量为0。
曼切斯特编码的缺点:
- 基频增加:基频是不归零编码的两倍,从而比特率变成了不归零编码的一半;
- 二义性:组合情况有两种。
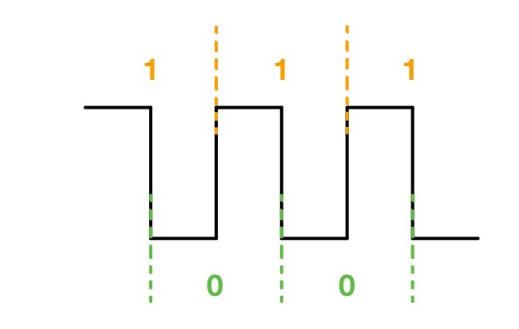
差分曼切斯特编码(Differential Manchester encoding):
解决曼切斯特编码的二义性。
“1”:自己的前半波与前一个编码的后半波相同;
“0”:自己的前半波与前一个编码的后半波相反。
有两种画法,初始为高、初始为低,两种画法结果对称。

差分曼切斯特编码的优点:
- 解决NRZ问题
- 解决二义性问题
差分曼切斯特编码的缺点(同曼切斯特编码):
- 基频翻倍
- 高频噪声增加
块编码(Block encoding)
- 将原信号每 m bits 分为一块;
- 把 m bits 的每块映射成 n bits 的块(m < n);
- 将 n bits 的块重新组合起来。

1.8 延时、丢包、吞吐量
延时(delay)
现实中的计算机系统不是理想系统,事件是随机突发的,所以不可避免的存在延时。

数据包的延时由四个部分组成:
处理时延(Nodal Processing Delay,dprocdproc)
路由器接收到分组对其进行处理的时间(比如差错检测),耗时很短,毫秒级。
排队时延(Queuing Delay,dqueuedqueue)
分组在链路上等待传输的时间,取决于先期到达的正在排队等待向链路传输的分组数量。
传输时延(Transmission Delay,dtransdtrans)
将分组的比特流传输到链路的时间(比如进行编码转换成查分曼切斯特编码的时间)。
如分组长度 L ,传输速率 R bps,则其传输时延为:
所以传输时间取决于分组长度和传输速率。
传播时延(Propagation Delay,$$)
信号在媒体上传播的时间。
如物理链路的长度 d,传播速度 s m/sec,则其传播时延为:
丢包
流量强度(traffic intensity)代表了路由器上排队的拥堵率。
其中,L —— 分组长度(bits);
R —— 链路带宽(bps);
a —— 平均分组到达速率
- 流量强度接近0时,几乎没有分组到达,排队延时很小;
- 流量强度0~1时,平均排队长度越来越长,排队延时越来越长;
- 流量强度接近1时,存在到达率超过传输时间间隔,拥堵。

路由器的排队容量是有限的,当分组到达一个已满的队列时,路由器将丢弃该分组,产生丢包。
吞吐量
从主机A到主机B传文件,B接收文件的速率为瞬时吞吐量(instantaneous throughput),单位bps;所有时间的平均速率为平均吞吐量(average throughput)。
串联链路吞吐量取决于瓶颈链路(bottleneck link)。

第二章 应用层
2.1 网络应用原理
- 可以在不同类型主机运行;
- 可以在不同终端间相互通讯;
- 在编写网络应用的过程中,不需要考虑网络核心设备,网络核心不会允许应用;
- 端系统上的应用可以快速开发,而且易于传播。
网络应用结构
客户机-服务器体系结构(Client-server architecture)C/S
例如:HTTP、IMAP、FTP
服务器:
- 永远在线;
- IP地址恒定;
- 服务器往往在数据中心,通过多台服务器进行扩展。
客户机:
- 可以和服务器进行通信;
- 可能间断性连接网络;
- 可能是动态的IP地址;
- 客户机之间不会直接通信;
点对点体系结构(Peer-peer architecture)p2P
- 没有一个一直在线的服务器;
- 任意端系统之间直接进行通信;
- 每个点(peer)向其他的点请求服务,同时作为回报也会提供相应的服务;
优点:自扩展性(self-scalability):新的点都会提供服务容量和负荷。
缺点:每个点都是间断性连接,而且IP地址会改变。
例子:P2P的文件分享。
1.进程通信
客户机和服务器进程
进程:一台主机上运行的程序。
在同一台主机上,两个进程通过进程间通信(inter-process communication)来进行通信。进程间通信由操作系统定义;
不同主机之间,进程通信同过报文交换,
比如并行计算中的MP和MPI,MP(Multi Processing)只能用于同一台主机间的通信,MPI(Message Processing Interface)主要用于不同主机之间的通信,也适用于同一台主机。
客户机进程(client process):发起通信的进程。
服务器进程(server process):等待连接的进程。
套接字(Sockets)
进程之间通过socket来接受/发送信息。
socket在进程通信中的作用相当于一个信封:
- 通信的信息需要装进socket
- 应用层下的各层作为基础设施,将信传到另一个进程
- 两个进程间的通讯会有两个socket

进程寻址(Addressing Processes)
如果两个主机之间的进程进行通信,发送端不仅要知道接收端的IP地址还需要知道进程相应的端口号。
IP地址:IPv4中32位IP,负责找到接收端主机。
端口号(port number):每台主机都可能运行着多个进程,每个进程对应一个端口号。
比如,HTTP服务端口号80、邮件服务端口号25。
应用层协议(Application-Layer Protocols)
网络应用的开发必须遵守网络协议。
应用层协议的分类
公开网络协议
- 定义在RFC中
- 统一标准,易于相互操作
- 例如:HTTP、SMTP
专用网络协议
- 一些非公开的网络协议
- 例如:Skype
应用层协议内容
应用层协议定义了
- 消息交换的类型:比如请求、响应
- 消息的语法:消息中有哪些字段以及这些字段如何定义
- 消息的语义:消息字段内容的含义
- 规则:进程什么时候、如何发送/接收消息
app对传输服务的需求
数据完整性(data integrity)
一些app需要100%可靠的文件传输,比如文件传输;有一些运行一部分的丢失,比如语音。
时效性(timing)
一些app要求较少的延时,比如对话直播。
吞吐率(throughput)
吞吐率,即最小带宽,一些app存在一个吞吐率下限才能正常使用,比如视频音频等多媒体;有些app运行弹性的吞吐率,比如邮件传输,吞吐率小可以慢慢传过去。
2.网络传输协议
- 传输层提供为应用层提供的俩种服务。
TCP(传输控制协议)
- 面向连接(connection-oriented):需要客户端和服务器之间能够建立连接
- 可靠传输(reliable transport):数据完整性高
- 流量控制(flow control):发送方不能发送太多数据导致接收方过载
- 阻塞控制(congestion control):不能有太多个主机同时发送导致网络过载
- 不提供的服务:时效性、最小带宽(吞吐率)、安全性
UDP(是一种不提供不必要服务的轻量传输协议。优点是速度快,灵活性好。)
- 不需要建立连接
- 不可靠的数据传输
- 不提供的服务:基本都不提供,不提供包括可靠传输、流量控制、阻塞控制、时效性、最小带宽(吞吐率)、安全性
不同app选择的网络传输协议

2.2Web和HTTP
World Wide Web 中的网页由超链接(hyperlink)连接。
- 页面由很多对象(object)组成,对象存储在服务器中;
- 对象有多种类型,可以是HTML文件,JPEG图片,动态脚本等等;
- 网页以HTML文件为基础,包括了许多参考对象,每个对象都可以通过URL来寻址。例如一张图片的URL为
www.someshcool.edu/someDept/pic.gif,其中www.someshcool.edu为主机名,/someDept/pic.gif为路径名。
HTTP协议概述
- 超文本传输协议(hypertext transfer protocol, HTTP)
网页的应用层协议。
基于客户-服务器体系结构。
- 客户机:负责请求,接收和显示Web对象。
- 服务器:Web服务器负责发送对象,响应客户机请求。
HTTP的传输层使用TCP
- 客户机发起TCP连接(创建socket,端口号80)
- 服务器接收TCP连接
- 在浏览器和网页服务器之间进行HTTP信息交换。
- TCP连接断开。
HTTP是无状态的。
- 服务器不会保留之前客户机发的请求信息。
- 协议要维持状态时很复杂的:保留之前的历史纪录很消耗;如果客户机或者服务器有死机,它们的状态会不一致,还需要重新同步。
HTTP消息类型:请求(request)与响应(response)
HTTP连接类型
非持久性连接(Non-persistent HTTP)
非持久性HTTP步骤
- TCP连接开启
- 通过这个TCP连接最多传输一个对象
- TCP连接关闭
如果加载多个对象时,需要多次非持久性HTTP连接。


非持久HTTP响应时间
RTT:往返时间(Round Trip Time),一个很小的数据包(处理文件的时间可忽略)从客户机传到服务器再传回来的时间。
HTTP响应时间(一个对象):
1个RTT:建立TCP连接的时间
1个RTT:HTTP请求以及收到HTTP响应的前几个字符的时间
对象/文件传输的时间
对一个对象来说,非持久性HTTP响应时间为

非持久性HTTP的问题
- 每传输一个对象都需要耗费
- 每建立一个TCP连接都会对操作系统(OS)产生负荷
- 并行抓取:浏览器常常开多个并行的TCP连接去抓取对象
- 每传输一个对象都需要耗费
持久性连接(Persistent HTTP)
持久性HTTP步骤
- 开启TCP连接
- 通过这一个TCP连接可以传多个对象
- TCP连接关闭
持久性HTTP特点(HTTP1.1)
- 服务器在发送响应后保持连接开启状态
- 后续这个客户机\服务器的HTTP消息都通过该开启的连接发送
- 两种发送对象方式:HTTP1.1采用流水的方式发送:一次性把对象全发了;另一种是客户机接收到一个对象后接着发下一个对象的请求
- 至少需要1个RTT发完所有对象
2.3 DNS
- 域名系统(Domain Name System,DNS)通过分布式的数据库来实现IP地址和域名的映射。
- 层级结构的域名服务器提供分布式的数据库
- 应用层协议:主机和域名服务器通过通信来实现IP地址和域名的转换
- DNS作为一个网络核心功能,为什么要放在应用层? 与网络结构设计理念有关,网络中主机很多映射很复杂,希望将复杂度留在端系统中,而不是在网络核心。
DNS服务
- IP地址和域名的转换
- 主机的别名
- 邮件服务的别名
- 负荷分配:有些Web可能有多个服务器,即会有多个IP地址对应一个域名,可调整IP地址的顺序以分配负荷。
DNS:分布式,层级的数据库
为什么要选用分布的DNS,而不是采用集中式的DNS。
- 单点可能失效:一个故障就全部gg了。
- 流量问题:所有客户机都访问一个域名服务器,会产生很大的流量。
- 远程的集中式数据库:客户机要访问可能要花费很多时间,RTT会很大,造成大延时。
DNS采用三层结构:
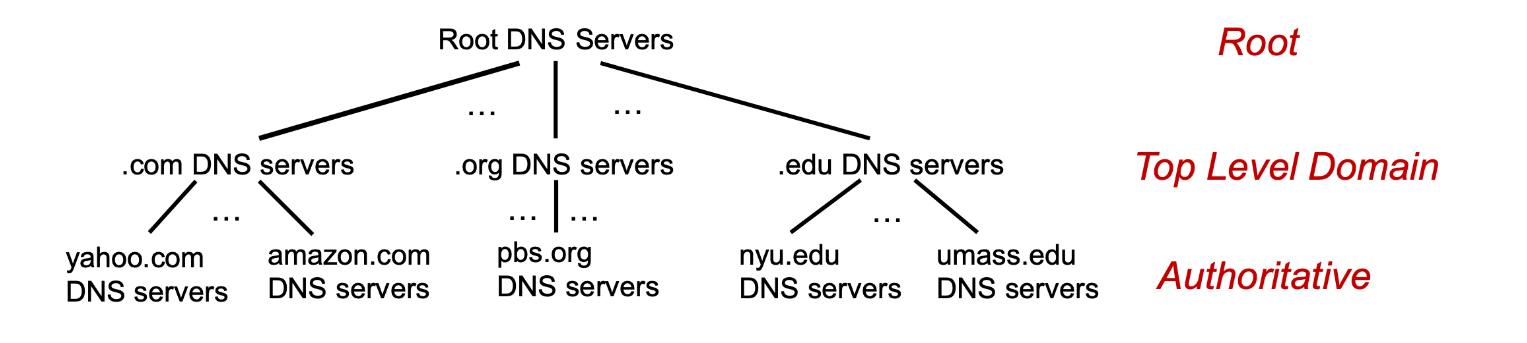
一个客户机得到www.baidu.com的IP地址的步骤:
- 客户机先查寻根域名服务器:得到顶级域名服务器.com DNS server的地址。
- 客户机查询顶级域名服务器:.com DNS server,得到权威域名服务器baidu.com DNS server地址;
- 客户机查询权威域名服务器:baidu.com DNS server,得到www.baidu.com的IP地址。
根域名服务器(Root Name Server)
- 官方的服务器,是连接的最后的方法(如果知道下级域名服务器的地址就不需要再从头开始查询根域名服务器,不然会对根域名服务器产生很大的流量负荷)。
- 对网络运行相当重要,离开根域名服务器网络无法正常工作。
- 域名系统安全扩展(Domain Name System Security Extensions,DNSSEC) —— 对DNS提供给DNS客户端(解析器)的DNS数据来源进行认证,并验证不存在性和校验数据完整性验证。
- ICANN(互联网名称与数字地址分配机构,Internet Corporation for Assigned Names and Numbers)—— 管理根域名服务器的组织。
- 世界上现在有13个根域名服务器,分布在世界各地。
顶层域名服务器(Top-Level Domain Server, TLD)
- 各种类型的TLD,比如
.com、.org、net、.edu等等,国家的TLD,比如.cn、.uk等等。 - Network Solutions:管理
.com、netTLD的组织 - Educause:管理
.edu的组织
- 各种类型的TLD,比如
权威域名服务器(Authoritative Domain Server)
- 组织自己的DNS服务器,用来提供组织内部的域名到IP地址的映射
- 由组织自己或者服务提供商来维护
本地域名服务器(Local DNS Name Server)
严格来说不属于层级结构
每个ISP都会有一个本地域名服务器,也叫做默认域名服务器(default name server)
当主机要进行DNS查询时,查询会被直接送到本地的DNS服务器。
作用:
- 缓存:可以缓存最近收到的域名到IP地址的映射(缓存有时效,会过期)
- 代理:可以作为代理,代替主机在层级结构中进行查询
DNS查询方法
迭代查询(iterated query)
- 被联系到的服务器会将后一个服务器的名字反馈回来,即“我不认识这个域名,但是你可以去问那台服务器(=゚ω゚)ノ”
- 下面的迭代查询过程,利用本地域名服务器作为代理迭代查询域名对于的IP地址。

递归查询(recursive query)
- 把域名解析的负担交给了联系到的域名服务器,这种方法对于高级的负担增加,所以一般采用迭代查询而不采用递归查询。

DNS缓存和更新
- 一旦域名服务器学习到了一个映射,它就会缓存这个映射。缓存往往在本地域名服务器里,这样可以减轻根域名服务器的压力。
- 缓存有效时间TTL,过了有效时间该缓存就会被删除。
- 更新/通知机制:由IETF制定的 RFC2136 标准。 如果中途域名主机改变IP地址,整个网络可能都不知道真正的IP地址,直到TTL到时,所以需要更新/通知机制。
DNS记录和消息
DNS记录
DNS的分布式数据库里存储了资源记录(resource record, RR)
RR的格式:
(name, value, type, ttl)type = A
- name:主机名
- value:对应的IP地址
type = NS
- name:域(如
foo.com) - value:对应的权威域名服务器的主机名
type = CNAME
- name:别名
- value:对应的规范主机名
- 比如
www.ibm.com是servereast.backup2.ibm.com的别名,这与负荷的分配有关,可能有多个服务器。
type = MX
- name:邮件服务器别名
- value:对应的规范主机名
DNS消息
DNS有两种消息类型:查询(query)和回答(reply),两种消息格式相同。
向DNS数据库插入记录
比如要创建一个
networkutopia.com的网站先在
.com的TLD提供商 Network Solution 注册networkutopia.com- 提供信息:域名、权威域名服务器的IP地址
- 提供商会向
.comTLD服务器插入 NS、A 的RR (networkutopia.com,dns1.networkutopia.com, NS) (dns1.networkutopia.com,212.212.212.1, A)
在自己的权威域名服务器上进行配置
- 插入
www.networkutopia.com的type A记录 - 如果是邮件服务,插入
networkutopia.com的type MX记录
- 插入
DNS查询工具
在命令行用
nslookup进行DNS查询。nslookup直接查询
- 查询一个域名的A记录,如果没指定dns-server,用系统默认的dns服务器。
xxxxxxxxxx11nslookup domain [dns-server]- nslookup查询其他记录
xxxxxxxxxx11nslookup -qt=type domain [dns-server]- type可以是以下这些类型:
type 类型 A 地址记录 AAAA 地址记录 AFSDB Andrew文件系统数据库服务器记录 ATMA ATM地址记录 CNAME 别名记录 HINFO 硬件配置记录,包括CPU、操作系统信息 ISDN 域名对应的ISDN号码 MB 存放指定邮箱的服务器 MG 邮件组记录 MINFO 邮件组和邮箱的信息记录 MR 改名的邮箱记录 MX 邮件服务器记录 NS 名字服务器记录 PTR 反向记录 RP 负责人记录 RT 路由穿透记录 SRV TCP服务器信息记录 TXT 域名对应的文本信息 X25 域名对应的X.25地址记录

2.4 P2P
点对点体系结构(Peer-peer architecture)
P2P概述
- 没有一个一直在线的服务器;
- 任意端系统之间直接进行通信;
- 每个点(peer)向其他的点请求服务,同时作为回报也会提供相应的服务;
- 优点:自扩展性(self-scalability):新的点都会提供服务容量和负荷。
- 缺点:每个点都是间断性连接,而且IP地址会改变。
- 例子:P2P的文件分享。
文件分发:客户机-服务器结构 vs P2P
从一个服务器分发大小为F的文件到N个节点需要多少时间?(每个节点上传和下载的速率都是有限的,网络中有足够的带宽)

如果选用客户机-服务器结构
服务器上传:需要上传这份文件 NN 次,上传速度为 usus,则需要的上传时间为 NF/usNF/us
客户机下载:每个客户机都需要下载文件,
客户机-服务器结构的分发时间:
此处的N导致耗费的时间随要下载的节点的数量线性增长,当要下载的节点数目大时,要耗费相当多的时间。
不需要先上传完再下载,参考第一章/网络核心/分组交换,以分组为单位发送,可以忽略上传到下载的时间。
如果选用P2P结构
服务器上传:服务器至少要上传1次文件,上传时间为
客户机下载:每个客户机都要下载文件,客户机最大下载时间为
客户机上传:每个下载了文件的客户机都可以上传文件,此时总上传速率可以达到
P2P结构的分发时间:
客户机-服务器结构和P2P分发时间对比

BitTorrent
文件分为大小为 256Kb的块(chunk)
每个节点负责上传和下载的文件块
追踪器(tracker):追踪参加洪流的节点
洪流(torrent):有一组节点相互交换文件块
新的节点想下载文件,先询问追踪器参加的节点,再从相近的节点处下载文件块

节点加入洪流:
- 本身没有文件块,但是随着时间的推移会从其他节点获取文件块
- 需要在追踪器进行登记,并且一般连接临近的节点
下载时,节点会上传文件块到其他节点
节点可以更改交换文件块的节点
节点随时会上线和下线
一旦节点有了完整的文件,它可以离开或者留在洪流中
请求文件块
- 在给定的时间,不同的节点拥有不同的文件块
- 一定周期,新的节点会问每个节点有哪些块
- 新节点会从其他节点处下载缺失的文件块 最稀缺优先(rarest first):如果有10个节点都有第1、2块,只有一个节点有第3块,则先下载第3块。
发送文件块
发送文件块遵守一报还一报原则(tit-for-tat)
- 节点会给目前给它发送文件块速率最高的四个节点发送文件块,其他节点就不发送了,每隔 10s 会选出新的top4
- 每隔 30s 会随机选择其他节点发送文件块,这样这个随机节点可能就会成为新的top4
- tit-for-tat原则:上传速率快的节点相应地得到高下载速率的回报。
2.5 socket编程
- 目标:建立客户机/服务器的应用中的通信运用socket
- socket:相当于应用进程和点对点传输协议之间的一扇门
- socket类型:对应TCP和UDP有两种socket
1. UDP中的socket编程
UDP:客户机与服务器之间没有连接
- 发送数据前不需要握手
- 发送数据包附加IP地址+端口号
- 接收方从数据包中提取处IP地址+端口号
- UDP提供的是一种不可靠的数据流传输,传输过程中可能会丢包,接收的时候顺序也可能被打乱。

UDP中的socket编程示例
这里jupyter notebook中进行编程,安装好jupyter notebook后,在命令行执行
xxxxxxxxxx11jupyter notebook即可启动jupyter notebook
UDP服务器代码:UDPServer.ipynb
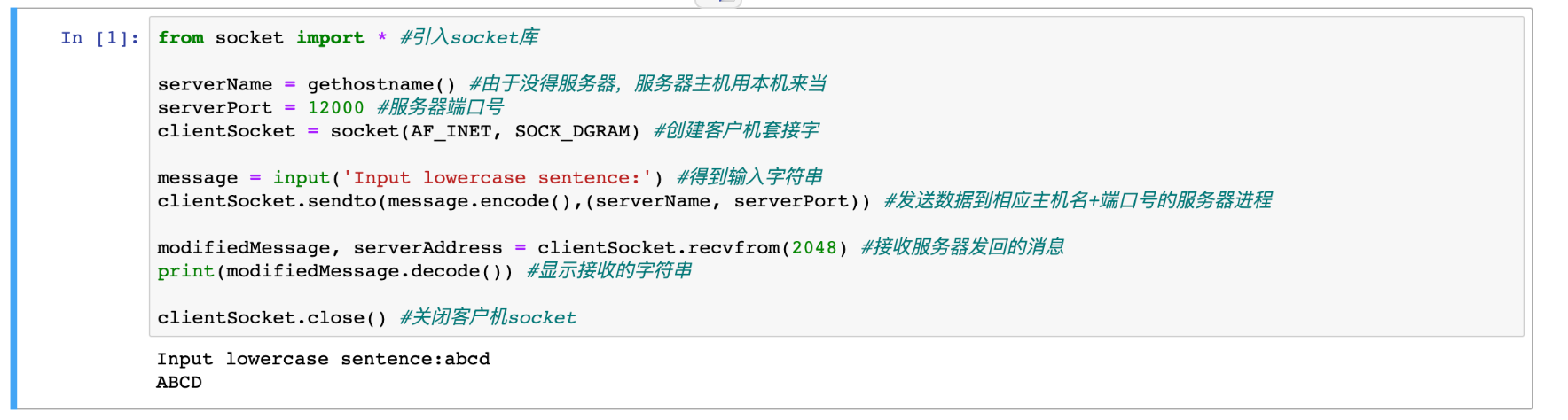
xxxxxxxxxx121from socket import * #引入socket库23serverPort = 12000 #服务器端口号4serverSocket = socket(AF_INET, SOCK_DGRAM) #创建服务器套接字5serverSocket.bind(('', serverPort)) #给套接字绑定端口号6print('The server is ready to receive.')78while True: #服务器要一直在线等待,所以给一个死循环9message, clientAddress = serverSocket.recvfrom(2048) #从服务器套接字中读取信息(发送的消息和客户机IP地址+端口号)10modifiedMessage = message.decode().upper() #对消息进行处理(此处是改大写)1112serverSocket.sendto(modifiedMessage.encode(), clientAddress) #将处理后的消息发回给客户机UDP客户机代码:UDPClient.ipynb
xxxxxxxxxx131from socket import * #引入socket库23serverName = gethostname() #由于没得服务器,服务器主机用本机来当4serverPort = 12000 #服务器端口号5clientSocket = socket(AF_INET, SOCK_DGRAM) #创建客户机套接字67message = input('Input lowercase sentence:') #得到输入字符串8clientSocket.sendto(message.encode(),(serverName, serverPort)) #发送数据到相应主机名+端口号的服务器进程910modifiedMessage, serverAddress = clientSocket.recvfrom(2048) #接收服务器发回的消息11print(modifiedMessage.decode()) #显示接收的字符串1213clientSocket.close() #关闭客户机socket先运行UDPServer.ipynb,启动服务器运行。

先运行UDPClient.ipynb,进行客户机访问。
2. TCP得socket编程
服务器的先行准备
- 服务器必须先运行
- 服务器需要创建socket来连接客户机
客户机连接服务器
- 客户机需要创建自己的socket,明确服务器进程的IP地址和端口号
- 客户机创建socket时,客户机和服务器之间需建立TCP连接
服务器接收客户机消息
服务器需创建一个新的socket,为了服务器进程能够和客户机进行通信
- 要运行服务器与多个客户机进行通信
- 用源的端口号来区分不同的客户机
- TCP提供的是一种可靠的字节流(byte-stream)传输(pipe)。
TCP中的socket编程示例
TCP服务器代码 :TCPServer.ipynb
xxxxxxxxxx171from socket import * #引入socket库23serverPort = 12000 #服务器端口号4serverSocket = socket(AF_INET, SOCK_STREAM) #创建服务器套接字(前台)5serverSocket.bind(('', serverPort)) #给套接字绑定端口号6serverSocket.listen(1)7print('The server is ready to receive.')89while True: #服务器要一直在线等待,所以给一个死循环10connectionSocket, addr = serverSocket.accept() #前台套接字接收到请求后,创建一个新的套接字(窗口)1112sentence = connectionSocket.recv(1024).decode() #窗口套接字读取信息13capitalizedSentence = sentence.upper() #对消息进行处理(此处是改大写)1415connectionSocket.send(capitalizedSentence.encode()) #将处理后的信息发回给客户机1617connectionSocket.close() #关闭窗口套接字,前台套接字保持开放TCP客户机代码:TCPClient.ipynb
xxxxxxxxxx141from socket import * #引入socket库23serverName = gethostname() #由于没得服务器,服务器主机用本机来当4serverPort = 12000 #服务器端口号5clientSocket = socket(AF_INET, SOCK_STREAM) #创建客户机套接字(类型为字节流SOCK_STREAM)6clientSocket.connect((serverName, serverPort)) #TCP连接78sentence = input('Input lowercase sentence:') #得到输入字符串9clientSocket.send(sentence.encode()) #发送数据到服务器1011modifiedSentence = clientSocket.recv(1024) #接收服务器发回的消息12print('From server:', modifiedSentence.decode()) #显示接收的字符串1314clientSocket.close() #关闭客户机socket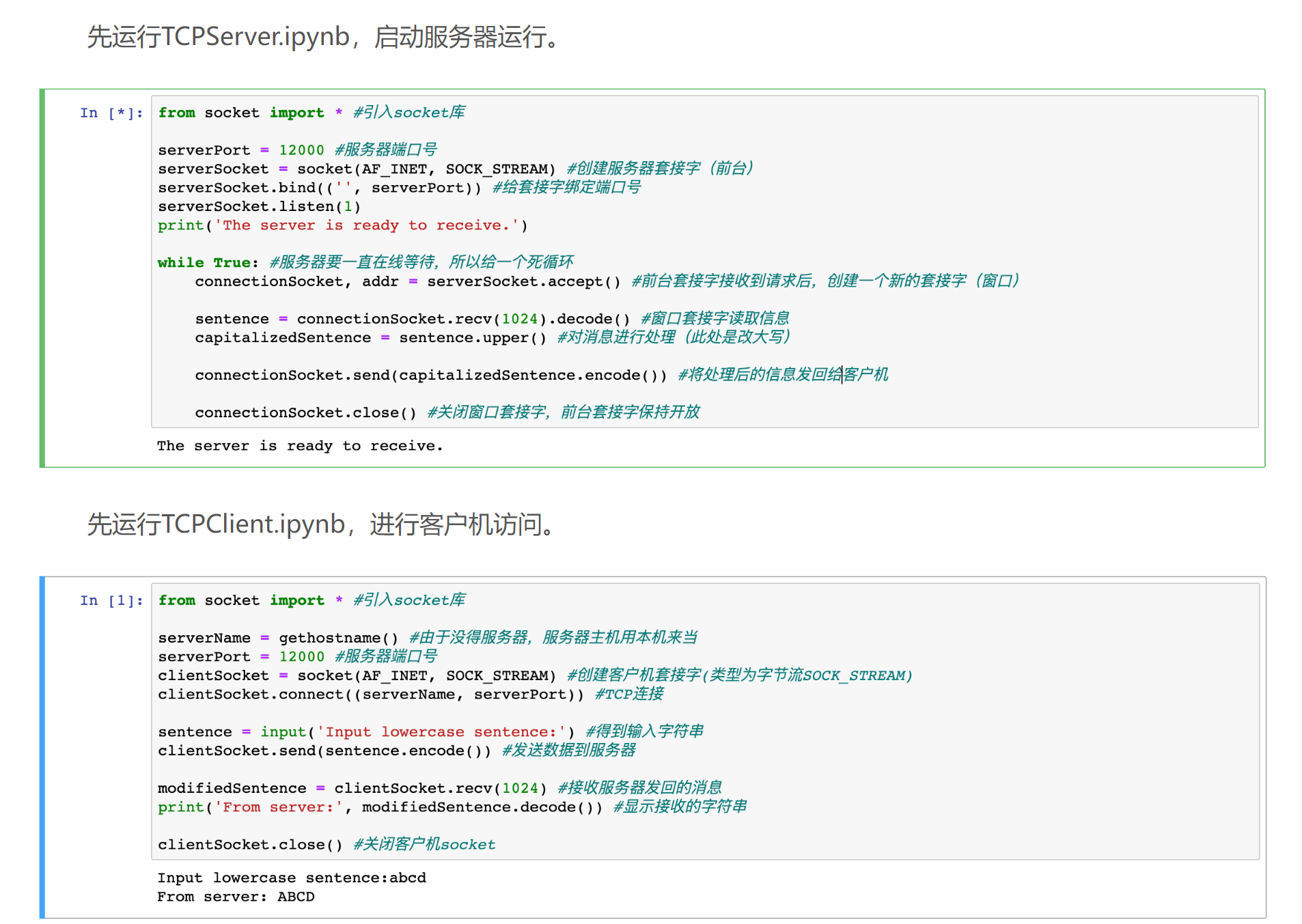
第三章 传输层
3.1传输层服务
传输层概述
为不同主机之间的应用进程提供通信的桥梁
端对端:传输层协议在端系统间运行,不需要涉及网络核心
- 发送方把应用层接到的消息分成段(segment),再把这些段传输给网络层
- 接收方把接收到的段重新拼装成消息,传输给应用层
传输层的协议:TCP和UDP
传输层和网络层对比
网络层:主机之间的通信
传输层:进程之间的通信
传输层依赖于并能强化网络层服务。
传输层协议
TCP:可靠的,有序的传送
拥塞控制
流量控制
需要建立连接
UDP:不可靠的,无序的传送
提供尽力而为交付服务
二者均不提供的服务:延时保障、带宽保障
3.2多路复用(Multiplexing)与多路分用(Demultiplexing)
- 多路复用存在于发送方:发送方需要处理多个套接字,并且给套接字加上传输层的头部。
- 多路分用存在于接收方:利用头部信息,将接收到的报文段传输给正确的套接字。

多路分用
多路分用工作流程
主机收到IP数据报(IP datagram)
- 每个数据报有源IP地址和目的IP地址
- 每个数据报携带一个传输层报文段(segment)
- 每个报文段有源和目的的端口号
主机利用IP地址和端口号来把报文段传入正确的套接字
无连接的多路分用(Connectionless demultiplexing)
- 参考UDP的socket工作方式,如果数据报的目的IP地址和端口号相同,它们将被传到同一个socket当中。(即使数据报的源可能不同)
面向连接的多路分用(Connection-oriented demux)
- 标记TCP的socket需要4元组:源IP地址、源端口号、目的IP地址、目的端口号
- 多路分用:接收方要用到上面4个值来传入不同的socket
- 服务器的主机可能要同时支持多个TCP连接
- web服务器有不同的socket对应每个连接的客户机,其中非持久性HTTP会给每个请求都建立新的socket。
3.3UDP
1.UDP概述
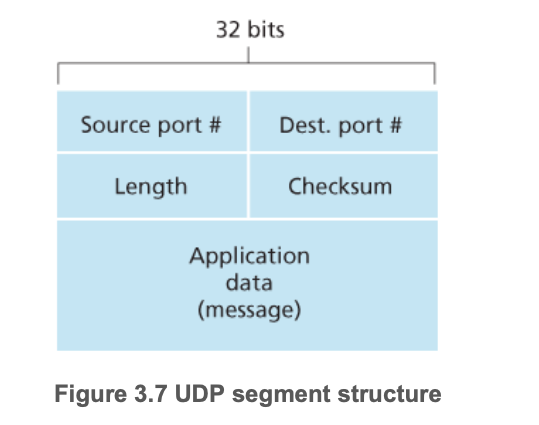
UDP(User Datagram Protocol,用户数据报协议),标准为RFC 768。
- 只有基本的功能
- 尽力而为的服务,UDP可能会丢包或者失序
- 不用连接:客户机和服务器不需要握手,每个UDP段都是独立处理的
UDP的优点
- 不需要进行连接,连接可能会造成时延
- 简单:不需要考虑连接的状态
- 相对小的头的大小
- 不需要拥塞控制,可以尽快地把UDP段发出去
UDP的应用
- 流媒体的app(运行一部分数据的丢失,但是对速度很敏感)
- DNS
- SNMP
通过UDP进行可靠的传输(UDP本身是不可靠的)
- 在应用层增加可靠性
- app要有对应的错误恢复方法
2.UDP校验和(UDP checksum)
位于UDP头部,负责检测传输的段有没有发生“错误”(比如位的翻转)
发送方:
- 把发送的段的内容包括头部分,当作一组16-bit的整数
- 校验和:报文段中的所有16-bit的和的取关于“1”的补码
- 发送方要将校验和放到UDP的校验和部分
接收方:
- 计算接收到的报文段的校验和
- 将接收方的校验和与发送方的校验和进行比较,不同则检测出错误,相同则没检测出错误
校验和相同只能说是“检验不出错误”,不能保障没有错误。比如传输中多个16bit字发生错误,但是可能恰巧相加校验和不变。

3.4可靠数据传输原理
可靠数据传输原理(Principles of reliable data transfer, rdt)
对应用层、传输层、链路层都很重要
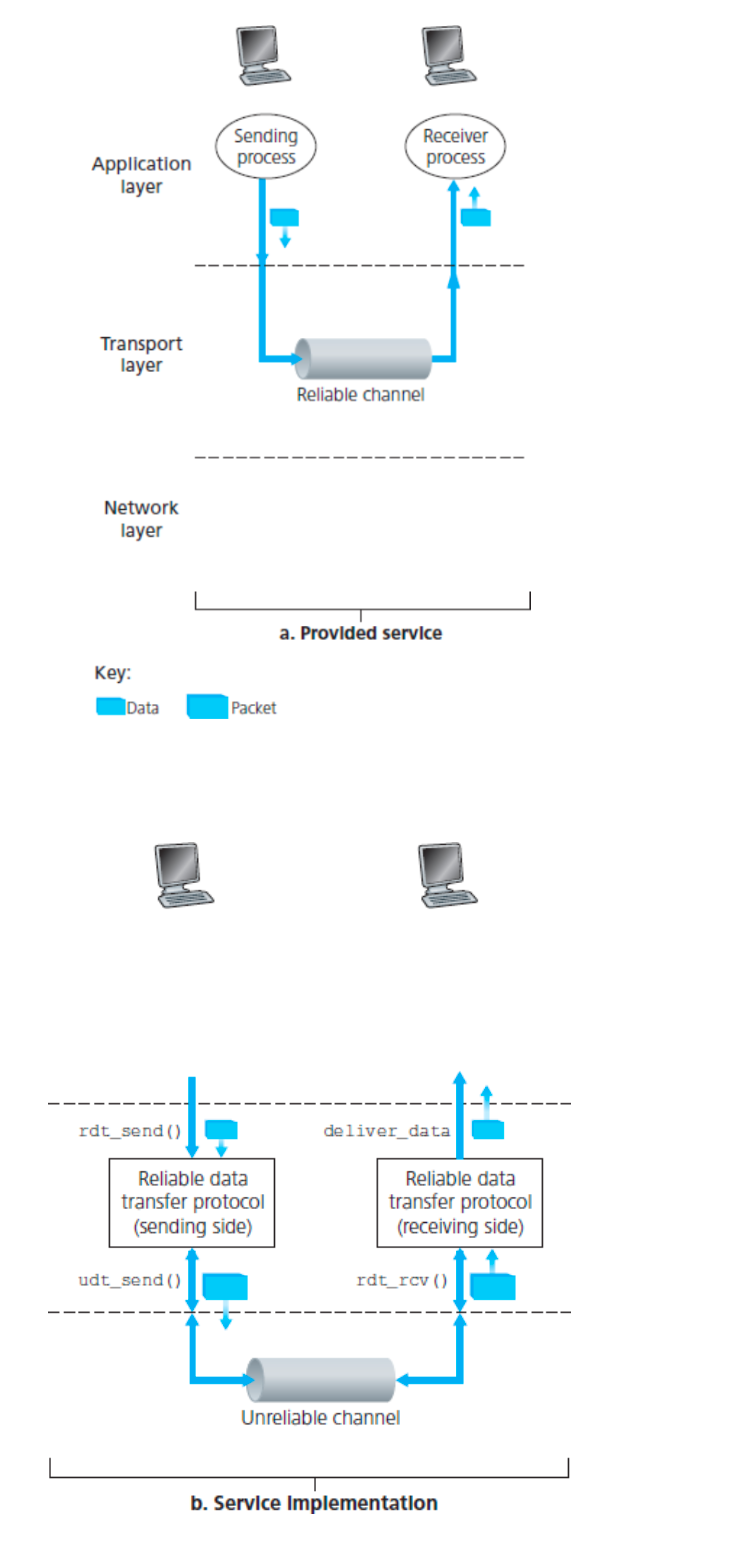
不可靠信道的特点决定了不可靠传输协议的复杂度
调用接口函数:
接口函数 参数 作用 rdt_send()data 调用数据传输协议的发送方,将要发送的数据交付给位于接收方的较高层 udt_send()packet rdt调用,通过不可靠信道,将packet传输到接收方 rdt_rcv()packet 在packet到达接收方信道时调用 deliver_data()data rdt调用,传输数据到高层 与不可靠信道之间的函数调用都是双向的,由于其不可靠性,需要进行确认的控制信号(ACK,NAK)。
1. rdt1.0:经可靠信道的可靠数据传输
rdt1.0概述
下层信道完全可靠:rdt1.0中假设下层的信道是一个完全可靠的信道(理想情况)
- 没有bit的错误
- 没有分组(packet)丢失
发送方和接收方的
有限状态机(FSM)
(存在状态和操作)
- 发送方发送数据给下层信道
- 接收方接收下层信道传来的数据
rdt1.0有限状态机
发送方
- 发送方首先在“等待上级调用”的状态,
rdt_send(data)上级调用rdt,从上级接收到data,make_pkt(data)将data装到packet里,再用udt_send(packet)将packet发送出去,完成后发送方再回到“等待上级调用”的状态。(发送方只有一个状态) 
- 发送方首先在“等待上级调用”的状态,
接收方
- 接收方首先在“等待下级调用”的状态,
rdt_rcv(packet)下级调用rdt,从下级接收到packet,用extract(packet, data)将packet重新恢复成data,提取出来的data再通过deliver_data(data)传送给上级。完成后接收方再回到“等待下级调用”的状态。 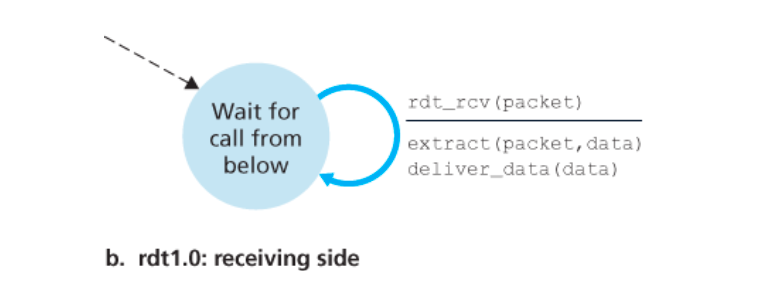
- 下层信道不可能完全可靠 => 引入rdt2.0
- 接收方首先在“等待下级调用”的状态,
2. rdt2.0:经具有比特差错信道的数据传输
引入差错检测、控制信号和重传机制,解决下层信道不可靠问题。
rdt2.0概述
packet在下层信道传输中会出现比特翻转:可以引入校验和(checksum)来检测比特错误。
错误恢复——如果检验到错误如何恢复?
- ACKs(acknowledgements):接收方告诉发送方收到的pkt是正确的
- NAKs(negative acknowledgements):接收方告诉发送方收到的pkt是错误的
- 发送方收到NAK则重传那个pkt
rdt2.0引入的新机制
- 差错检测:checksum
- 接收方反馈:控制信号(control msg),即ACK和NAK
- 重传
rdt2.0无限状态机
发送方
- rdt2.0的发送方有2个状态——等待上级调用、等待ACK或NAK。发送方最初处于“等待上级调用”的状态,
rdt_send(data)上级调用rdt,从上级接收到data,sndpkt = make_pkt(data, checksum)将data装到packet里,再用udt_send(sndpkt)将packet发送出去。此时,发送方变为“等待ACK或NAK”的状态。rdt_rcv(rcvpkt)接收反馈,如果isNAK(rcvpkt)即接收到NAK,则重传udt_send(sndpkt),并保持“等待ACK或NAK”的状态;如果isACK(rcvpkt)即接收到ACK,则回到“等待上级调用”的状态。 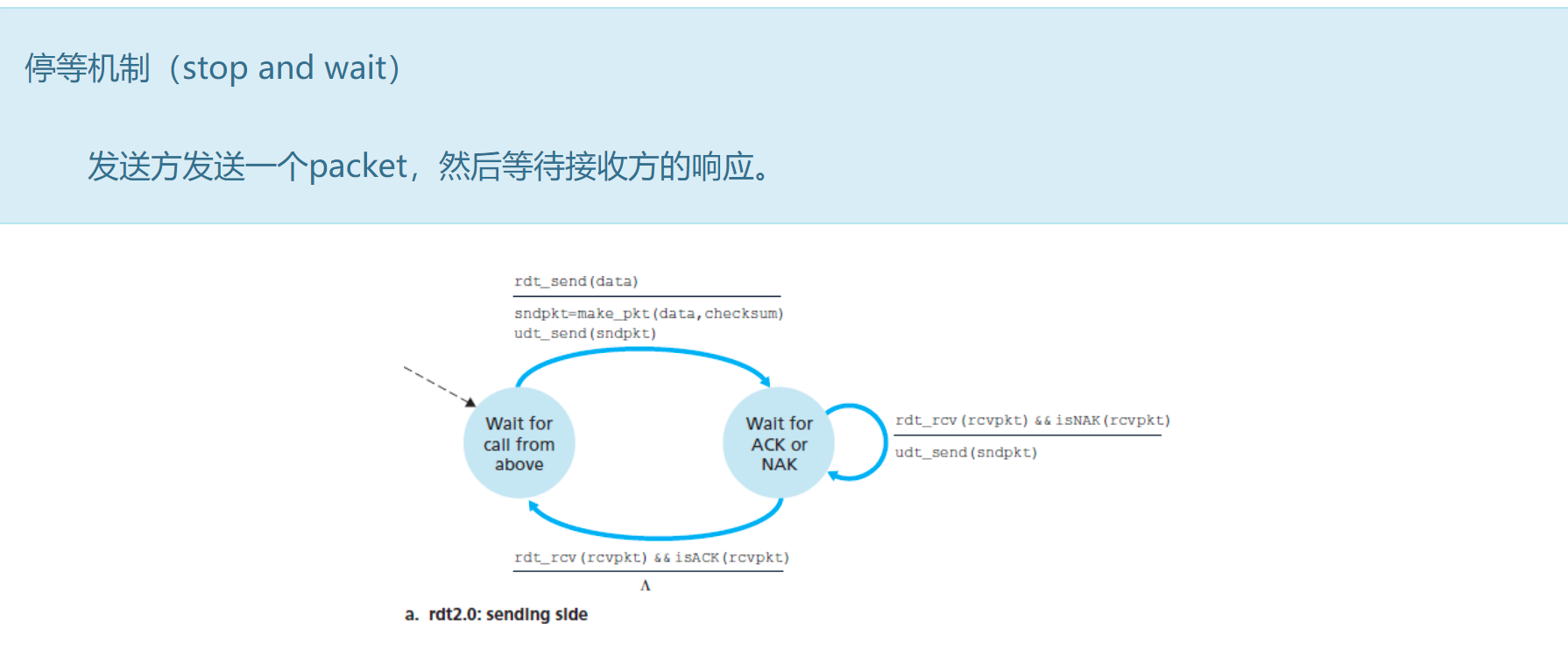
- rdt2.0的发送方有2个状态——等待上级调用、等待ACK或NAK。发送方最初处于“等待上级调用”的状态,
接收方
- 接收方还是只有一个状态——等待下级调用。接收方首先在“等待下级调用”的状态,
rdt_rcv(rcvpkt)接收方接收packet,如果corrupt(rcvpkt),即检测到错误,则udt_send(NAK)反馈NAK;如果notcorrupt(rcvpkt),即未检测到错误,则extract(packet, data)将packet重新恢复成data,deliver_data(data)将data传送给上级,最后udt_send(ACK)反馈ACK。完成后接收方再回到“等待下级调用”的状态。 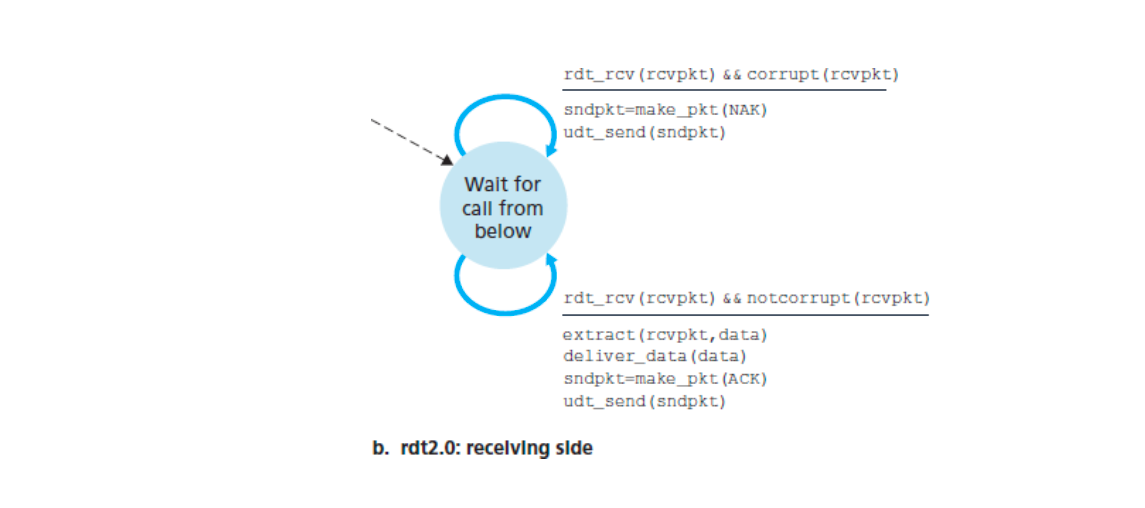
- 接收方可能判断ACK/NAK信号出错,导致发送分组重复 => 引入rdt2.1
- 接收方还是只有一个状态——等待下级调用。接收方首先在“等待下级调用”的状态,
3. rdt2.1:接收方判断ACK/NAK信号出错
- 引入0/1序号和丢弃分组,解决接收方判断ACK/NAK信号出错,导致发送分组重复问题。但这也让发送方和接收方有限状态机的状态翻倍。
rdt2.1有限状态机
发送方
- 相较于rdt2.0,rdt2.1在发送的packet里包含了0/1序号(sequence number),所以发送方有4种状态——等待上级调用 0、等待ACK或NAK 0、等待上级调用 1、等待ACK或NAK 1。
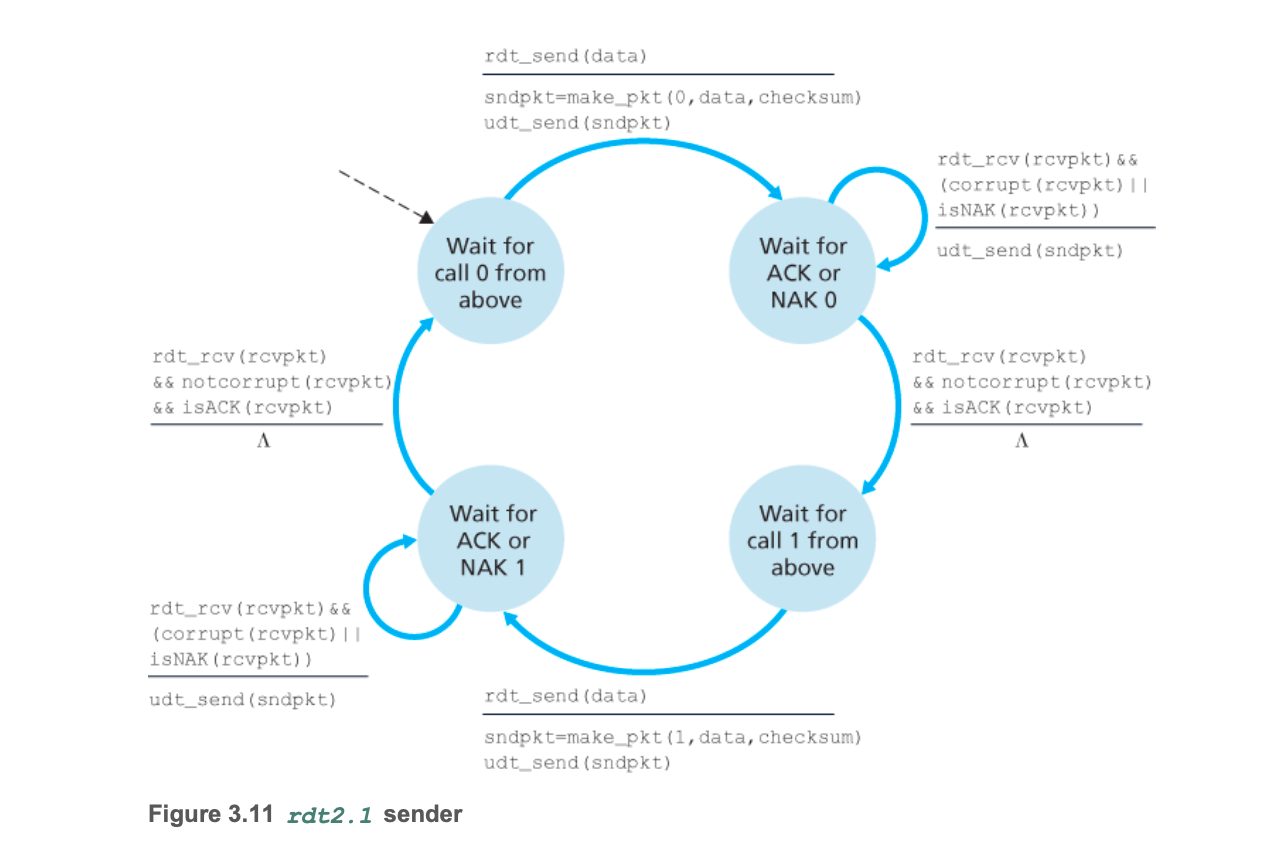
接收方
- 接收方有2种状态——等待下级调用 0、等待下级调用 1。只有在数据包ACK且收到的packet序号与目前状态等待的序号相同时,才能向上传输。


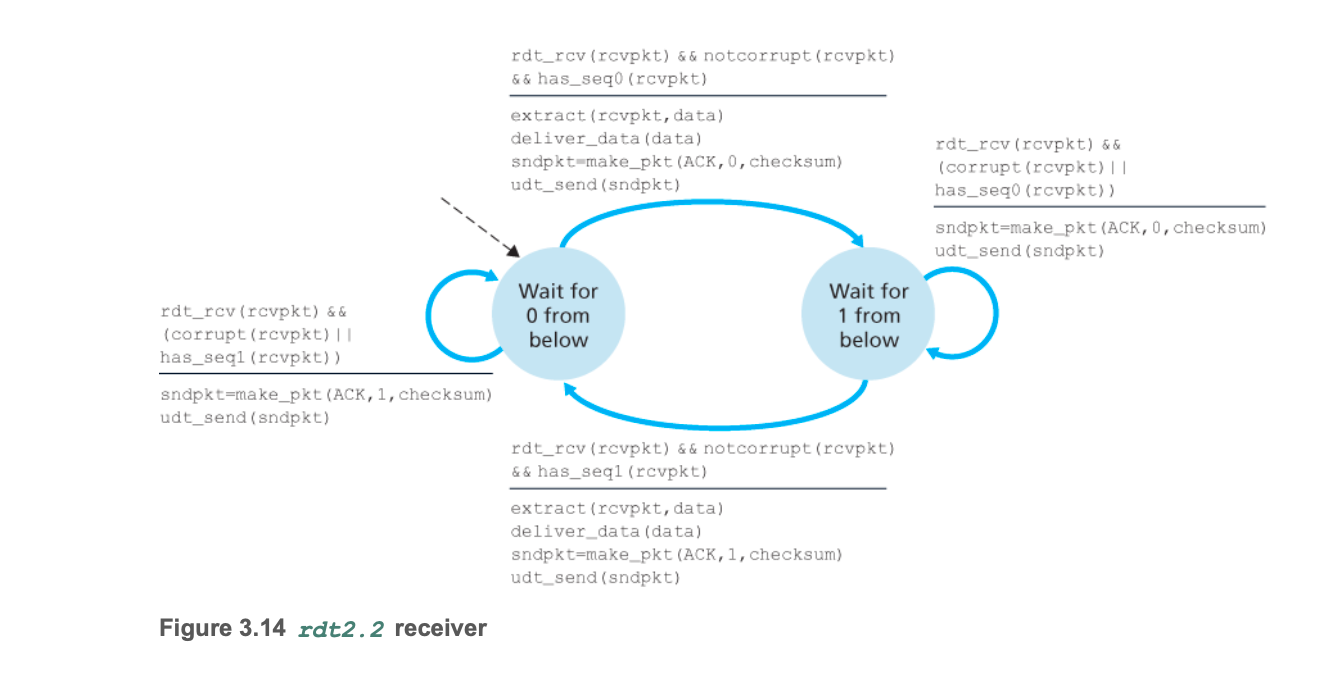
4. rdt2.2:不发送NAK的协议
- 用重复的ACK替代NAK,解决信号冗余问题。
rdt2.2概述
- 只用ACK,不用NAK,实现和rdt2.1一样的功能。
- 在检测到错误时,不发送NAK,但是接收方要发送判断上一次序号的ACK(同时包括序号)
- 用重复的ACK代替NAK
rdt2.2有限状态机
发送方
- 将rdt2.1中的
isNAK(rcvpkt)判断本次反馈是NAK,替代成判断上次序号的反馈是ACK,比如rdt2.2在“等待ACK 0”时,如果isACK(rcvpkt, 1),则相当于收到来rdt2.1中的isNAK(rcvpkt)。其余不变。 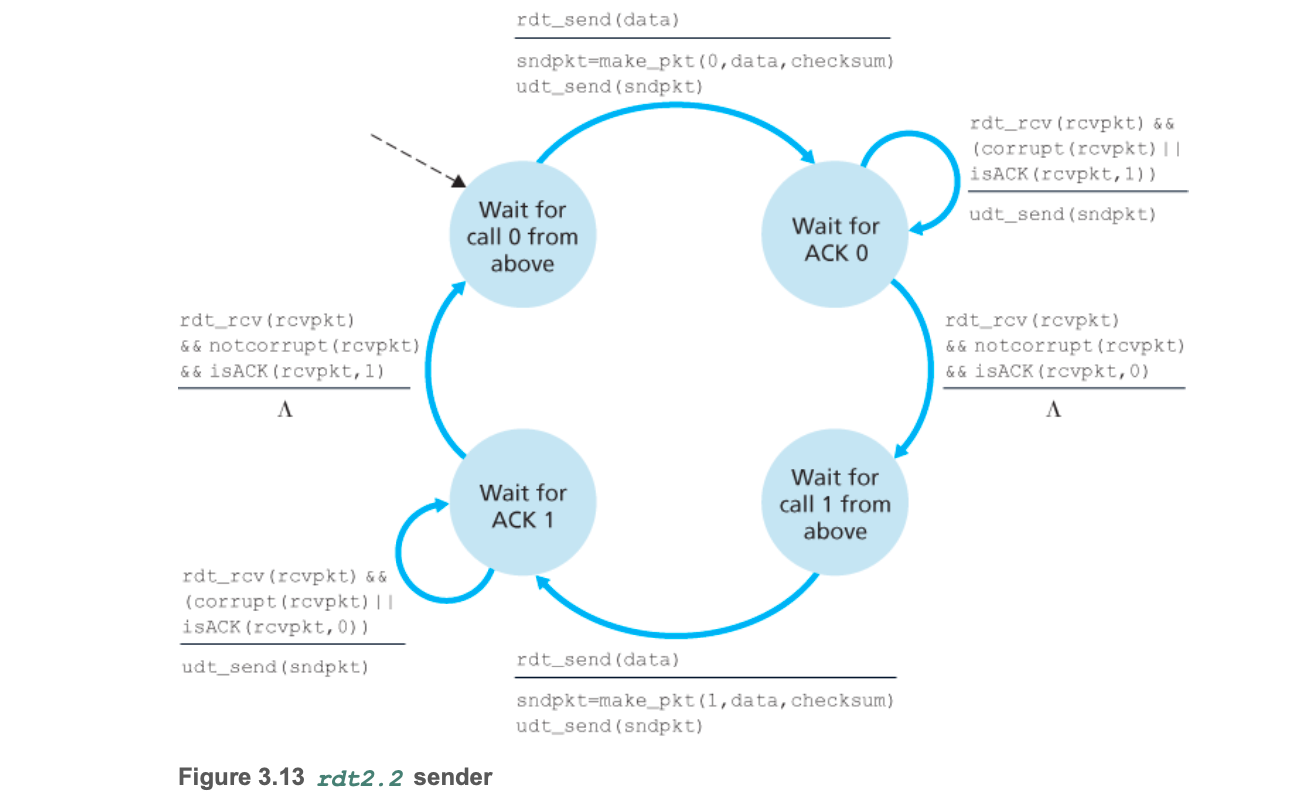
- 将rdt2.1中的
接收方
- 接收方如果校验和检测出错,则发送上一次序号的ACK;在校验和检测正确时,发送ACK也需要带上本次的序号。
5. rdt3.0:信道存在错误和丢包
rdt3.0概述
发送端在一个合理的时间内,等待接收ACK。
- 当在等待时间内没有接收ACK时,重传
- 超过时间可能有两种情况:丢包或时延,如果发生时延可能会重复发生pkt,此时rdt2.1和2.2中的序号可以解决问题,同样的发生ACK得带上序号。
- 需要计时器
rdt3.0有限状态机
- 发送方传输开始时,
start_timer启动计时器。如果timeout传输超时,则重新启动计时器;如果在规定时间内接收到反馈,则stop_timer结束计时。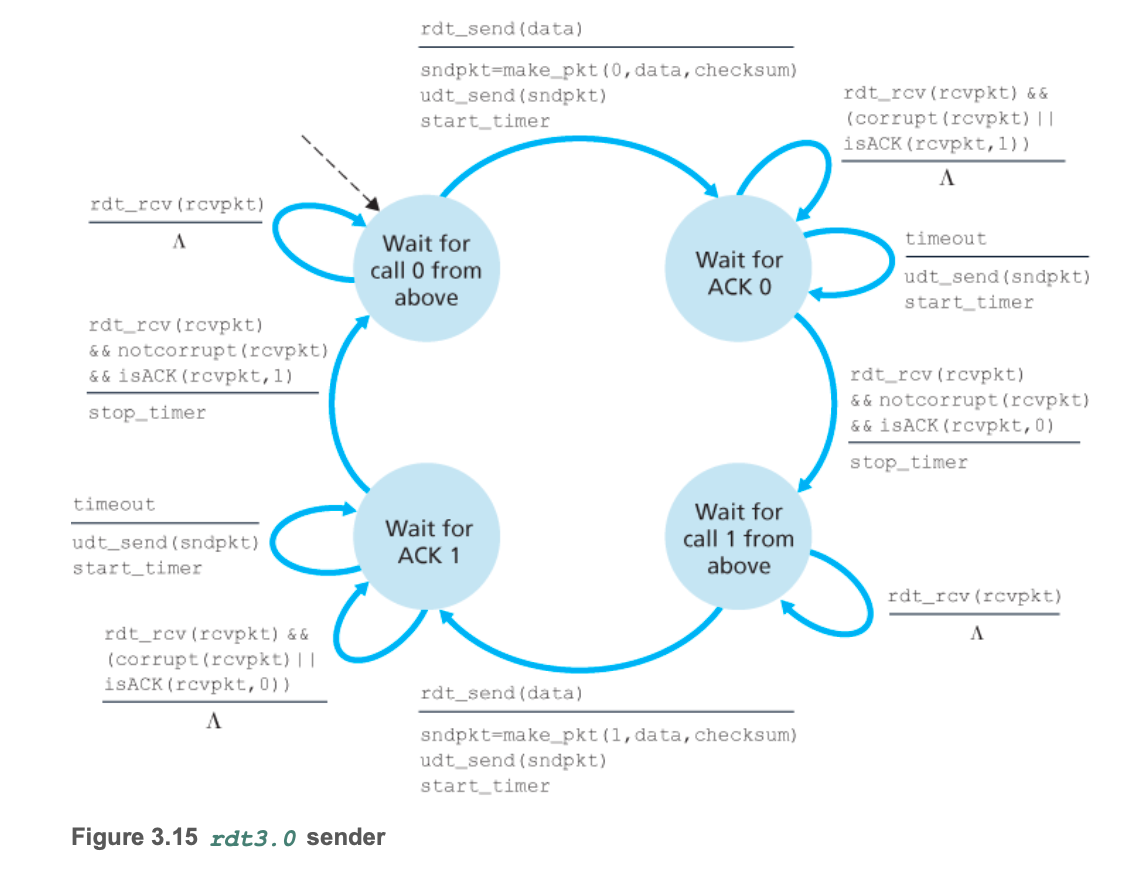
- 发送方传输开始时,
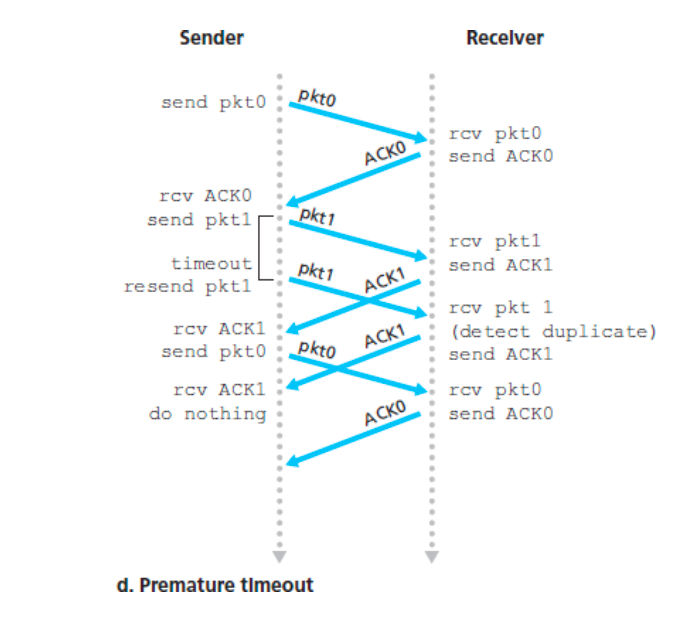
rdt3.0流程
- 正常流程

- 丢packet
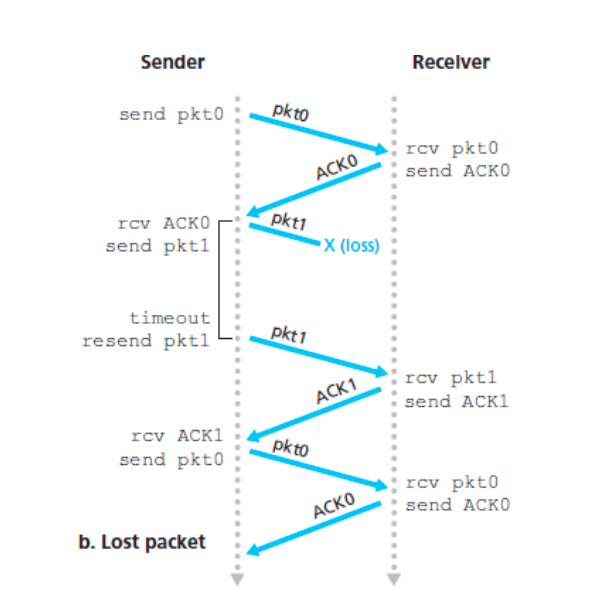
- 丢ACK
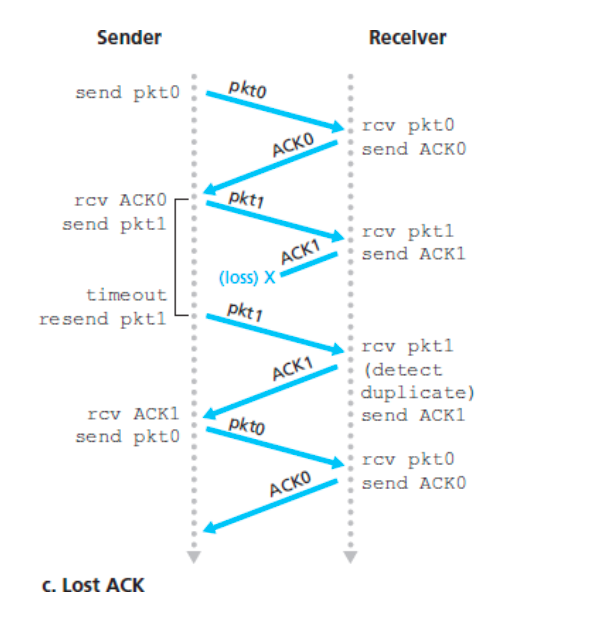
- 超时
- 正常流程
rdt3.0性能
- rdt3.0性能很差

- rdt3.0网络协议限制了物理资源的使用率。
- rdt3.0性能很差
3.6流水线协议
采用流水线的机制,不要等一个RTT发送回来再发下一个(即不再采用停等机制),来提高物理资源的使用率。
- 图 停等机制(Stop-and-wait)

- 图 流水线机制(Pipelined Operation)

1.回退N步(Go-back-N,GBN)
- 发送方可以有至多N个没有ACK的packet同时在流水线上
- 接收方只发送累计ACK
- 发送方给最早还没ACK的packet一个计时器,当这个计时器到时时,重传所有的未ACK的packet。
GBN发送方
- packet头部有k bit的序号,则可以表示
- “窗口”大小为N,这一段是允许的未ACK的packet

- ACK(n)累计确认:ACK在发送的时候要带上序号#n,即#n及之前的packet都收到了。接收方发送ACK n,则证明#n及之前的packet都收到了。否则接收方还是发送之前的ACK(重复)。
- 计时器只给最早的未ACK的packet保留
- 如果timeout(n),重传#n以及比#n更大的未ACK的packet

- packet头部有k bit的序号,则可以表示
GBN接收方
发送的ACK是顺序接收到的packet里面最大的序列号#
- 可能会产生重复的ACK
- 只需要记住期望的序列号(expextedseqnum)
乱序到达的packet
- 直接丢弃,不缓存(缓存会造成数据重复)
- 重新发送顺序最大序列号#

GBN流程


2. 选择重传(Selective Repeat,SR)
接收方分别确认所有正确收到的pkt
- 缓存pkt,最终有序传给上层
发送方重发没ACK的pkt
- 发送方给每个还没ACK的packet都维持一个计时器
发送方的window
- N个连续的序号
- 限制发送并且未ACK的pkt

SR发送方
收到上层数据
- 如果window里还有可用序列,则继续发送
timeout(n)
- 重发
pkt n,重启timer
- 重发
如果
ACK(n)在可接收范围内[sendbase,sendbase+N−1]- 将
pkt n标记为接收完成 - 如果 n 是最小的未ACK的pkt,则将window滑动到下一个未ACK的pkt
- 将
SR接收方
如果
pkt n在接收范围内[rcvbase,rcvbase+N−1][rcvbase,rcvbase+N−1]- 发送
ACK(n) - 如果不是按序到达,则缓存pkt
- 如果是按序到达,则向上交付已有的按序的缓存,并将window滑动到下一个未收到的pkt
- 发送
如果
pkt n在[rcvbase−N,rcvbase−1][rcvbase−N,rcvbase−1]内- 发送
ACK(n)
- 发送
其他情况忽略
SR流程

SR困境
- 比如下面序列号有:#0, #1, #2, #3,window大小为3的情况。SR会无法分清a、b两种情况,导致在b中误判重发的第一轮的
pkt0,被当作后一轮的pkt0填入。 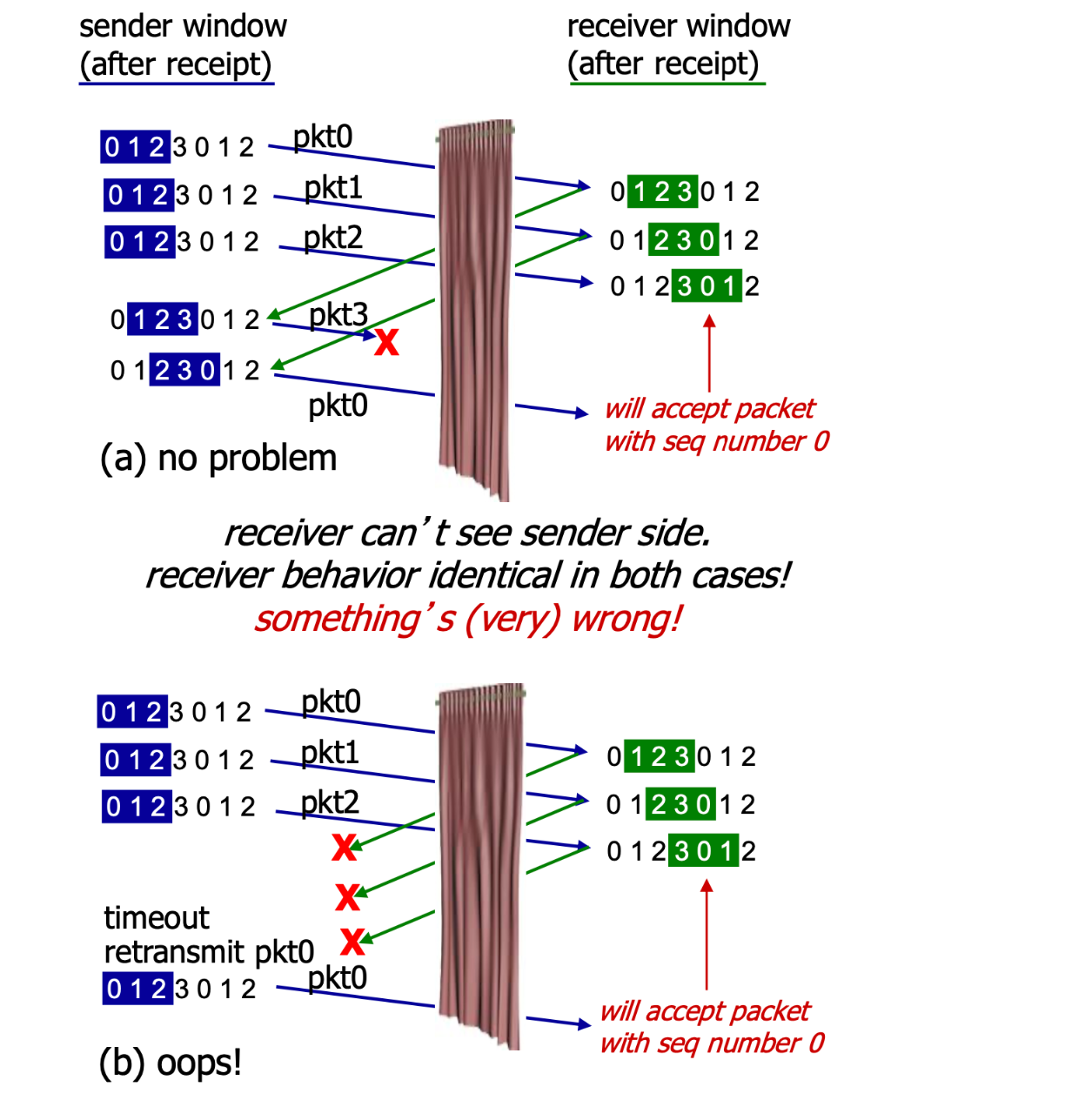
- 比如下面序列号有:#0, #1, #2, #3,window大小为3的情况。SR会无法分清a、b两种情况,导致在b中误判重发的第一轮的
3.7TCP
1.TCP概论
点对点(point-to-point):一个发送方、一个接收方
可靠的、有序的字节流
- 没有消息的边界
流水线机制
- 窗口大小由拥塞和流量控制
全双工
- 同时双向数据流
- MSS(maximum segment size):最大报文段长度
面向连接
- 握手:交换控制信息,初始化发送方和接收方的状态
流量控制
2.TCP报文段结构

端口号:用来标识同一台计算机的不同的应用进程。
- 源端口:源端口和IP地址的作用是标识报文的返回地址。
- 目的端口:端口指明接收方计算机上的应用程序接口。
- TCP报头中的源端口号和目的端口号同IP数据报中的源IP与目的IP唯一确定一条TCP连接。
序号和确认号:是TCP可靠传输的关键部分。序号是本报文段发送的数据组的第一个字节的序号。在TCP传送的流中,每一个字节一个序号。e.g.一个报文段的序号为300,此报文段数据部分共有100字节,则下一个报文段的序号为400。所以序号确保了TCP传输的有序性。确认号,即ACK,指明下一个期待收到的字节序号,表明该序号之前的所有数据已经正确无误的收到。确认号只有当ACK标志为1时才有效。比如建立连接时,SYN报文的ACK标志位为0。
数据偏移/首部长度:4bits。由于首部可能含有可选项内容,因此TCP报头的长度是不确定的,报头不包含任何任选字段则长度为20字节,4位首部长度字段所能表示的最大值为1111,转化为10进制为15,15*32/8 = 60,故报头最大长度为60字节。首部长度也叫数据偏移,是因为首部长度实际上指示了数据区在报文段中的起始偏移值。
保留:为将来定义新的用途保留,现在一般置0。
控制位:URG ACK PSH RST SYN FIN,共6个,每一个标志位表示一个控制功能。
- URG:紧急指针标志,为1时表示紧急指针有效,为0则忽略紧急指针。
- ACK:确认序号标志,为1时表示确认号有效,为0表示报文中不含确认信息,忽略确认号字段。
- PSH:push标志,为1表示是带有push标志的数据,指示接收方在接收到该报文段以后,应尽快将这个报文段交给应用程序,而不是在缓冲区排队。
- RST:重置连接标志,用于重置由于主机崩溃或其他原因而出现错误的连接。或者用于拒绝非法的报文段和拒绝连接请求。
- SYN:同步序号,用于建立连接过程,在连接请求中,SYN=1和ACK=0表示该数据段没有使用捎带的确认域,而连接应答捎带一个确认,即SYN=1和ACK=1。
- FIN:finish标志,用于释放连接,为1时表示发送方已经没有数据发送了,即关闭本方数据流。
窗口:滑动窗口大小,用来告知发送端接受端的缓存大小,以此控制发送端发送数据的速率,从而达到流量控制。窗口大小时一个16bit字段,因而窗口大小最大为65535。
校验和:奇偶校验,此校验和是对整个的 TCP 报文段,包括 TCP 头部和 TCP 数据,以 16 位字进行计算所得。由发送端计算和存储,并由接收端进行验证。
紧急指针:只有当 URG 标志置 1 时紧急指针才有效。紧急指针是一个正的偏移量,和顺序号字段中的值相加表示紧急数据最后一个字节的序号。 TCP 的紧急方式是发送端向另一端发送紧急数据的一种方式。
选项和填充:最常见的可选字段是最长报文大小,又称为MSS(Maximum Segment Size),每个连接方通常都在通信的第一个报文段(为建立连接而设置SYN标志为1的那个段)中指明这个选项,它表示本端所能接受的最大报文段的长度。选项长度不一定是32位的整数倍,所以要加填充位,即在这个字段中加入额外的零,以保证TCP头是32的整数倍。
数据部分: TCP 报文段中的数据部分是可选的。在一个连接建立和一个连接终止时,双方交换的报文段仅有 TCP 首部。如果一方没有数据要发送,也使用没有任何数据的首部来确认收到的数据。在处理超时的许多情况中,也会发送不带任何数据的报文段。
TCP序号
- 报文段(segment)的序号:字节流第一个字节的序号

TCP ACK
TCP报文的ACK填写:期望从另一方收到的下一个字节序号
- 主机A接收到从主机B传来的字节#0~535,A下一个期望接到的字节#为536,所以主机A发送的报文段的ACK中填536。
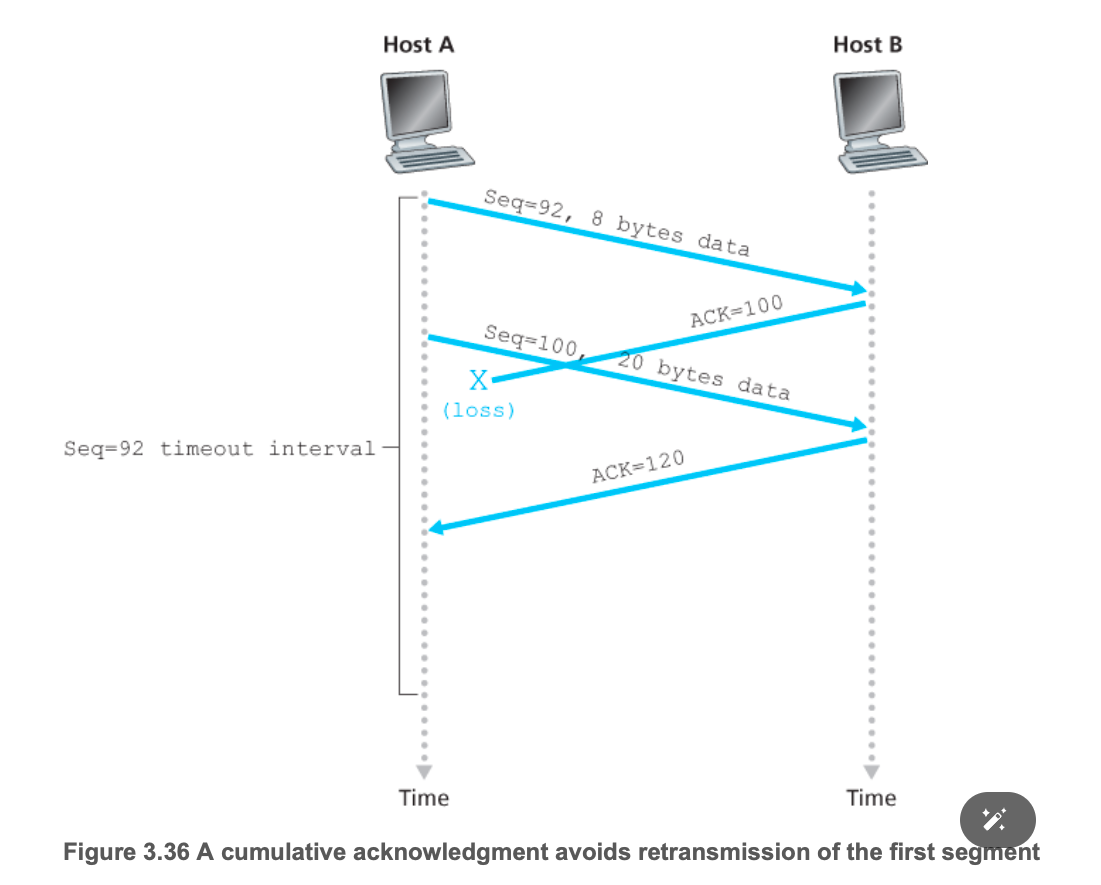
累计ACK(cumulative ACK):与GBN相似
- 主机A接收到从主机B传来的字节 #0~535 和 #900~1000,A下一个期望接到的字节#依旧为536,所以主机A下一个发送的报文段的ACK中填536。
TCP 序号和ACK传输
TCP计时
如何设置TCP timeout值?
- 不能太短:过早timeout造成不必要的重传
- 不能太长:对丢包反应太慢
如何EstimateRTT(估计RTT)?
- SampleRTT(样本RTT):计算发送segment到接收ACK的时间,忽略重传
- SampleRTT多次测量取平均
则EstimateRTT为
- 指数加权移动平均(不是线形的,存在迭代使原来的SamleRTT的系数越来越小,越靠后的越接近当前网络状态)
- EstimateRTT的变化通常比SamleRTT变化更加平滑
- 一般,α=0.125
DevRTT(偏差RTT)为(一般β=0.25β=0.25)
重传超时间隙(TimeoutInterval)

3. TCP可靠数据传输
TCP的rdt服务是建立在IP的不可靠传输上的。
- 流水机制
- 累计ACK
- 一个timer
重传触发情况
- 超时
- 重复ACK
TCP简化
- TCP简化版:无重复ACK,拥塞控制和流量控制。
TCP sender
TCP sender的3种事件
从上一层收到数据
分段,创建seq#(报文中字节流第一个字节的序号)
开始timer
- 只给最早一个未ACK的segment timer
- 用Timeoutlnterval作为timeout时间
超时
- 重传segment
- 重启timer
收到ACK
如果收到未ACK的segment的ACK
- 更新被ACK的segment标记
- 从最近的一个未ACK的segment开新的timer
图TCPsender简化版

TCP重传情况
- 图ACK丢包

- 图 提前timeout
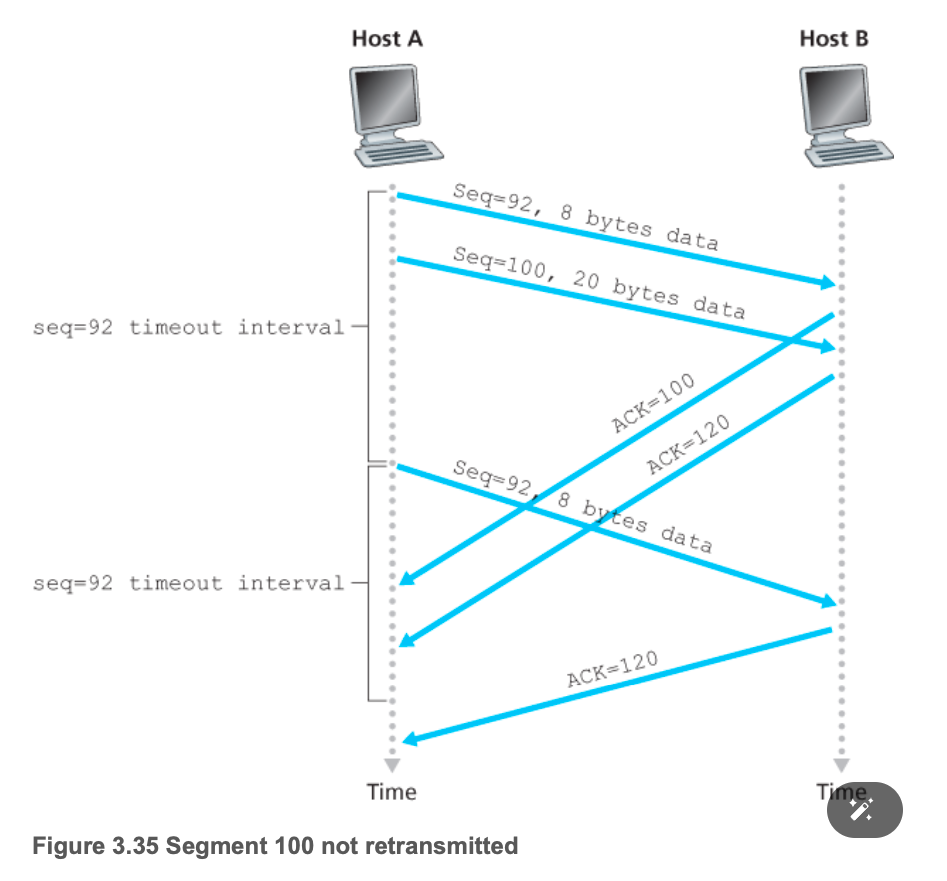
- 图累计ACK
- 图ACK丢包
TCP receiver
| 事件 | TCP接收方反应 |
|---|---|
| 具有所期望序号的按序报文段到达。所有在期望序号及以前的数据都已经被确认 | 延迟的ACK,对另一个按序报文段的到达最多等待500ms。如果下一个按序报文段在这个时间间隔内没有到达,则发送一个ACK |
| 具有所期望序号的按序报文段到达。另一个按序报文段等待ACK传输 | 立即发送单个累计ACK,以确认两个按序报文段 |
| 比期望序号大的失序报文段到达。检测出间隔 | 立即发送冗余ACK,指示下一个期待字节的序号(其为间隔的低端的序号) |
| 能部分或完全填充接收数据间隔的报文段到达 | 倘若该报文段起始于间隔的低端,则立即发送ACK |
TCP快速重传
timeout时间长,造成长时延
通过重复的ACK检测丢包
- 发送方发送很多个segment
- 如果有segment丢失,则可能会收到很多个重复的ACK
TCP快速重传机制:
- 如果发送方收到对同一个数据收到3个重复的ACK(实际收到4次该ACK),则认为此时未ACK的segment丢失,不需在等待timeout,重发ACK的最小seq#

- 如果发送方收到对同一个数据收到3个重复的ACK(实际收到4次该ACK),则认为此时未ACK的segment丢失,不需在等待timeout,重发ACK的最小seq#
4.流量控制
接收方要控制发送方,使发送方不会发送得太快导致接收方的缓存(buffer)溢出。
接收方告诉发送方free buffer大小,包含在TCP报文的rwnd(receive window中)
- Rcbuffer socket设定大小(一般,4096)
- 一些操作系统也可以自动刁姐RcvBuffer
图接受方缓存
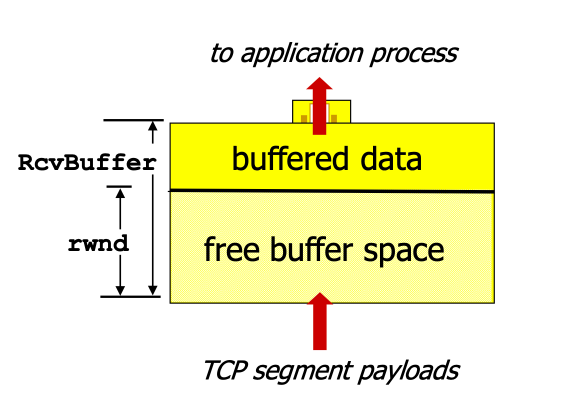
sender通过rwnd来限制unacked segment的数量
保障receive的buffer不会溢出
- 如果sender接收到rwnd = 0,此时没有剩余buffer,再发送数据会造成receiver buffer溢出,但是要防止锁住。
- 所以sender向reeiver发送一个1byte data的报文,以更新rwnd。
5. 连接管理
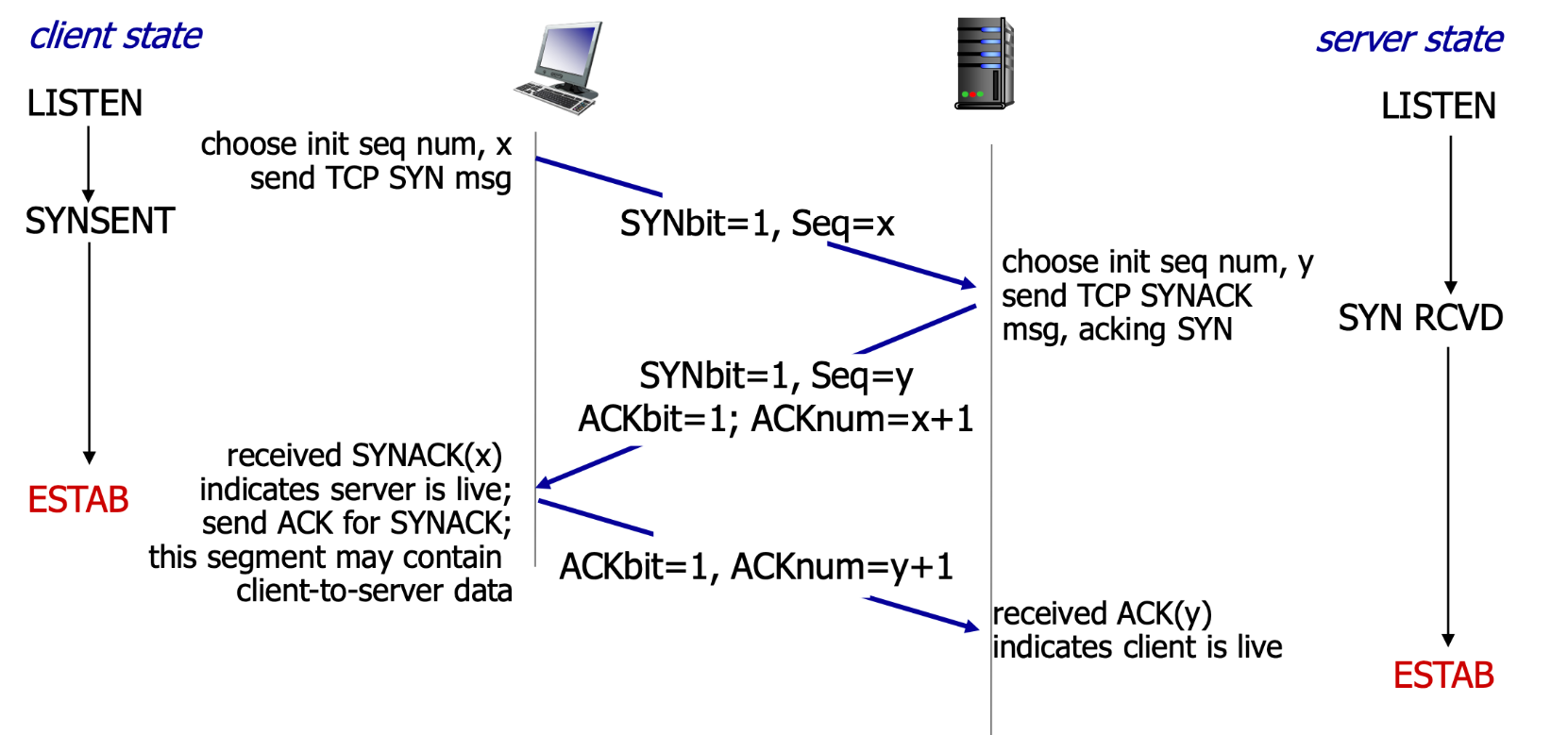
1. TCP建立连接:3次握手
建立连接之前,先握手
- 双方同意建立连接
- 同意连接的参数

- 图 TCP 3次握手
2. TCP关闭连接:4次挥手
client、server俩边都可关闭连接
- 发送TCP segment的 FIN bit = 1
用ACK回应FIN(ACK可以和FIN一起发)
同时收到FIN也可以处理(双工)
图 TCP 关闭连接
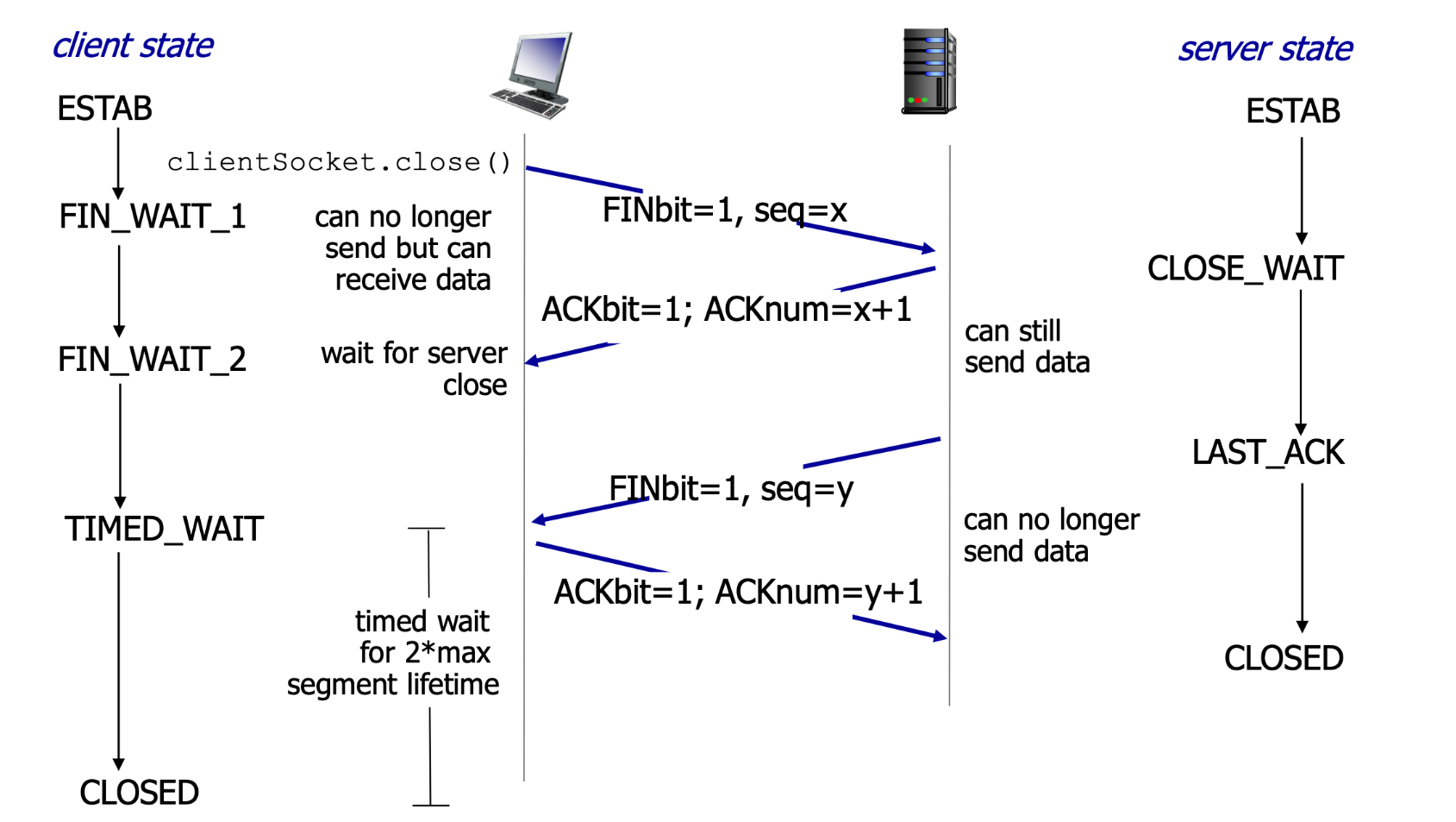
图 TCP 双方状态循环
6.拥塞控制原理
拥塞:
- 非正式定义:太多的源发送数据太多太快,导致网络无法处理
- 和流量控制不同(流量控制c-s一对一)
- 产生丢包、延时
- 网络前十的问题
场景一:2个Sender, 和1个无限buffer的Router
- 2个sender,2个receiver
- 1个router带无限buffer
- 输出链路的容量:R
- 没有重传(无限buffer不会丢包)

- 图 输入速率-输出速率

- 图 输入速率-时延

场景二:2个Sender, 和1个有限buffer的Router
一个router、有限buffer
重传timeout的packet
- 正常理想情况下:
情况一(理想):sender只在router的buffer有空时才发送
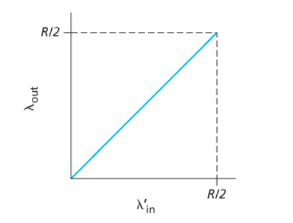
情况二:知道丢包,当router的buffer满了,packet丢失。sender只有在知道丢包时才重传。
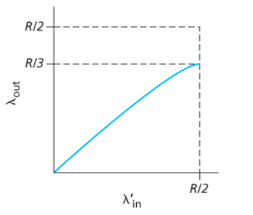
情况三:重复packet
- 在router的buffer满时,packet可以丢包
- 提前timeout,会导致发送两个相同的packet

拥塞代价
- 排队延时
- 丢包导致重传
- 提前timeout导致非必要的重传,pkt重复,降低吞吐量
- 当一个packet被丢弃,其上游提供给这个packet的传输容量都浪费了
3.8TCP拥塞控制
1. 概述
sender逐渐增加发送速率(window size),从而探查可用bandwidth,直到丢包
- 加性增(additive increase):cwnd每次每个RTT增加 1 MSS 直到检测到丢包(MSS 最大报文段长度)
- 乘性减(multiplicative decrease):如果发生丢包,cwnd减半
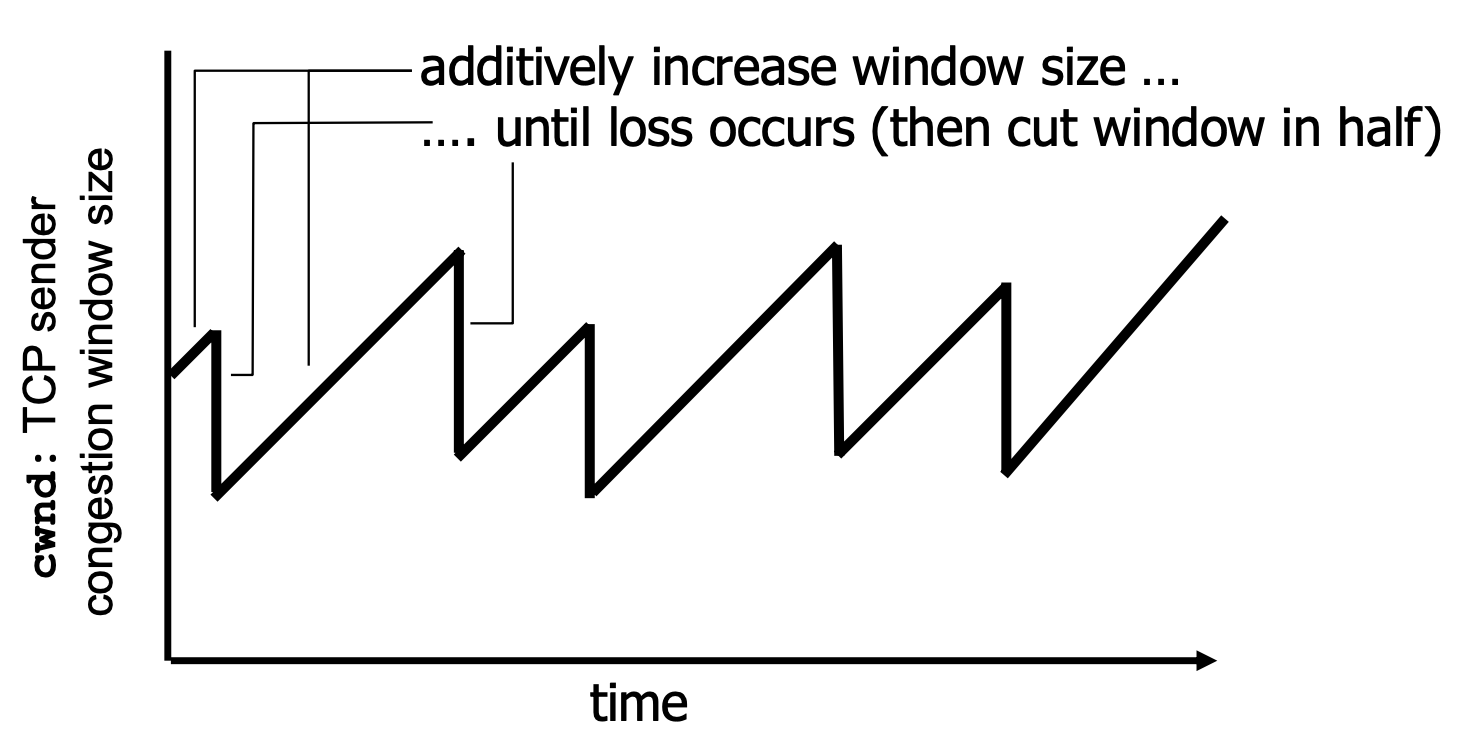
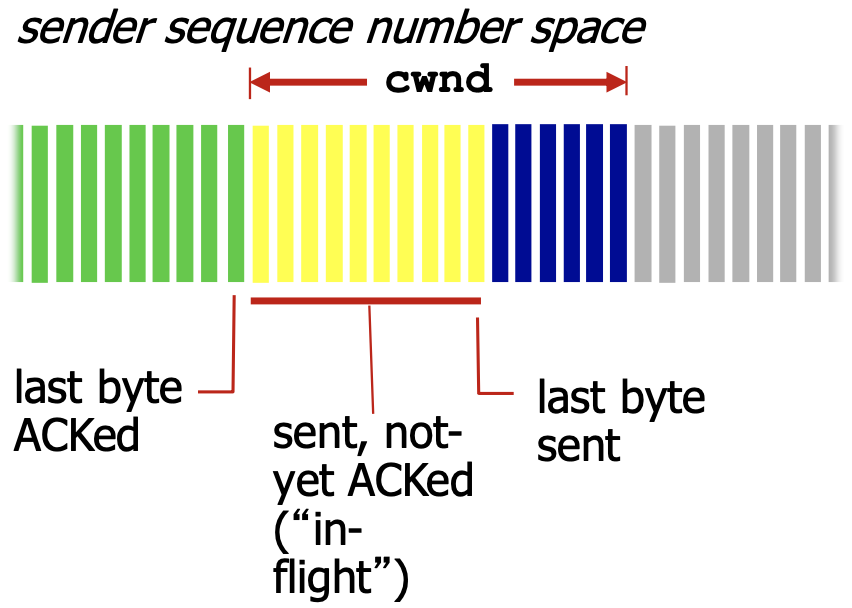
sender传输限制
cwnd是动态的随着网络拥塞程度变化的函数
结合之前的rwnd,实际的窗口大小为
TCP发送速率(TCP sending rate)
发送cwnd bytes,等待1个RTT接收ACK,然后再发送后续的bytes。
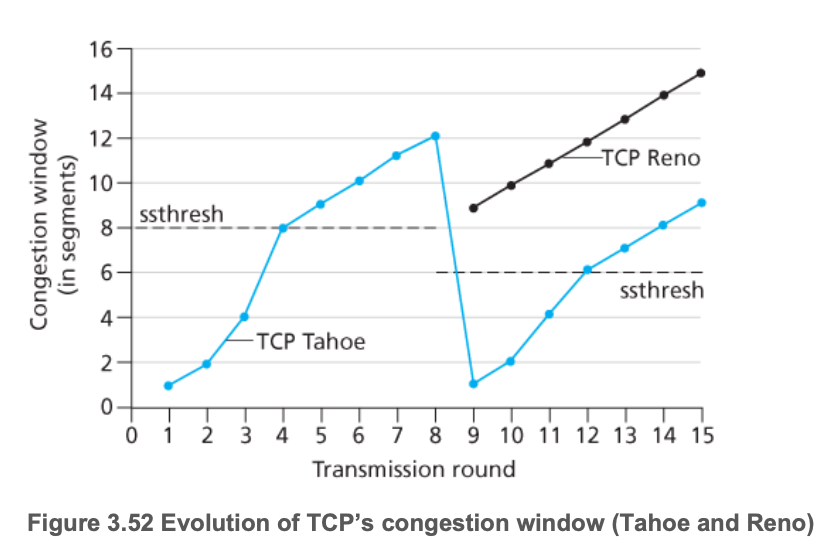
2. TCP慢启动(TCP slow start)
连接开始时,先指数级增长发送速率,直到出现
丢包
- 初始,cwnd=1 MSScwnd=1 MSS
- 每经过一个RTT,翻倍cwnd(实际上,每收到一个ACK,cwnd+1)

当出现丢包时,
timeout情况
- cwnd重新设为 1MSS
- 重新开始慢启动,直到到达一个threshold
3个重复的ACK情况(TCP RENO版本)
- 重复的ACK既然能收到,那么网络还是有一定的传输能力,不需要像timeout一样重开。
- cwnd减半(乘性减)
TCP Tahoe版本中,timeout和3个重复的ACK都将cwnd设为 1MSS
3.从 slow start 到 CA 的转换
当cwnd达到上次timeout时的1/2(即sstresh)时,从指数级增长变成线形增长。
sstresh —— 出现丢包时,将sstresh设置为此时cwnd的1/2
图 TCP Tahoe/Reno下cwnd的变化图【注:中间有一次3次ACK的丢包】
4.TCP拥塞控制FSM

5.TCP吞吐量
avg TCP throughput(TCP平均吞吐量)由window size 和 RTT 决定(忽略slow start,假设一直由data在发送)
W:丢包时的 window size,avg window size 为

6.高速TCP
假设一条具有 1500byte 报文段和 100ms RTT 的TCP连接,用此连接以 10Gps 发送数据。此时平均拥塞窗口长度为 83.333 个报文段。TCP连接的吞吐量公式(单位 bytes/sec):
10Gps的吞吐量,报文段丢失概率为
7.TCP公平性
目标:K条TCP连接,经过R bps的瓶颈,每条TCP连接分 R/Kbps,则公平。
以两条TCP连接为例,从A出发,经过加性增、乘性减,会逐渐趋向公平线。所以TCP可以实现公平性。

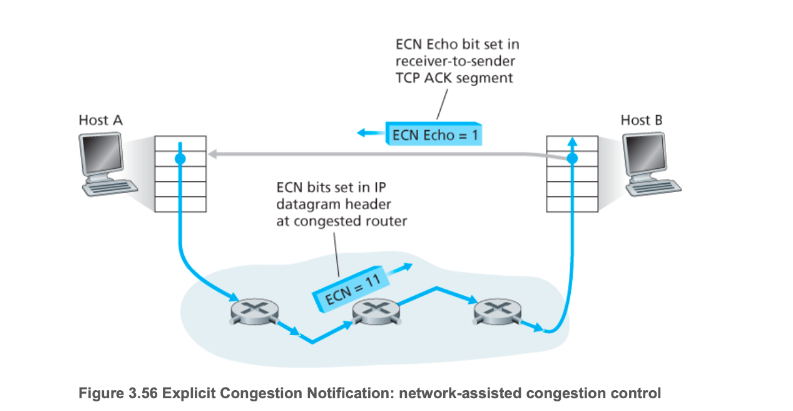
8.Explicit Congestion Notification(ECN)
网络辅助的拥塞控制
- ToS field(IP datagram头部的 2 bits)可以被网络路由标记,以显示拥塞
- ToS field会被送到receiver的主机
- receiver在发送给sender的ACK中嵌入ECE,来通知sender有拥塞
第四章 网络层(Network Layer)
4.1概述
- 在发送和接收的主机之间传送packet
- 路由器(router)要检验通过的IP数据报(IP datagram)的头部
1. 网络层功能
- 路由(Routing):决定packet从源到目的路径
- 转发(Forwarding):将packet从route的输入端口到合适的输出端口
- 连接建立(Connection setup):一些网络结构要求数据传输前先建立路由路径
2. 网络层服务
- 确保交付(Guaranteed delivery)
- 具有时延上界的确保交付(Guaranteed delivery with bounded delay)
- 有序分组交付(In-order packet delivery)
- 确保最小带宽(Guaranteed minimal bandwidth)
- 安全性服务(Security)
网络层提供尽力而为的服务(best-effort service)。

4.2 虚电路和数据报网络(Virtual circuit and datagram networks)
- 数据报网络是无连接的服务
- 虚电路是面向连接的服务
- 端到端的服务、运行在网络核心
1.虚电路(Virtual circuit,VC)
- 呼叫建立 -> 数据传输 -> 呼叫拆除
- 每个packet携带VC号
- 路径上的每个router会给每个经过的VC维护连接状态
- 链路、路由资源(带宽、缓存)都会分配到VC

VC组成:
- 从源到目的的路径
- VC号:路径上每个链路都有一个号码(可以变化)
- 转发表
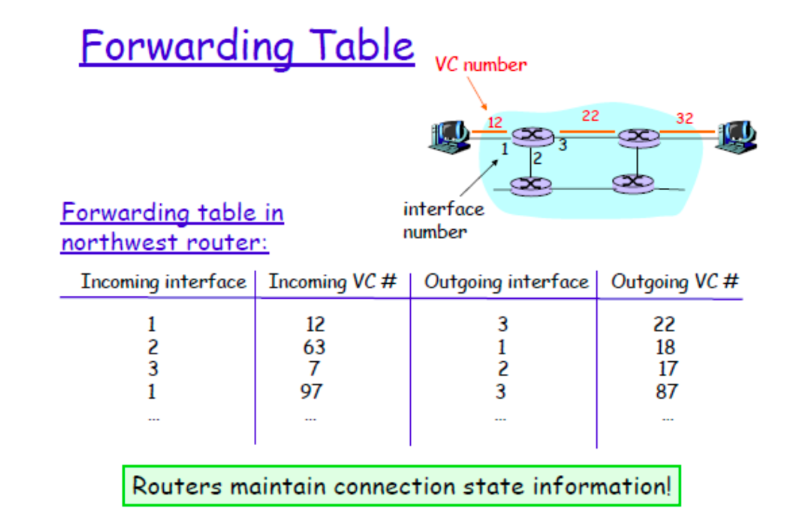
路由维持连接状态的信息。
信令协议(signaling protocol)
VC采用信令协议(signaling protocol)
- 用来建立、维护、拆除VC
- 用在ATM、frame-relay、X.25
- VC在Internet中没有使用
数据报网络(Datagram networks)
- 无连接
- 路由没有端到端的连接状态
- packet通过目的主机ID来路由,同一个源到目的的packet可能走不同的路径。

转发表存储地址范围对应的链路接口,比如
| Destination Address Range | Link Interface |
|---|---|
| 11001000 00010111 00010000 00000000 ~ 11001000 00010111 00010111 11111111 | 0 |
| 11001000 00010111 00011000 00000000 ~ 11001000 00010111 00011000 11111111 | 1 |
| 11001000 00010111 00011001 00000000 ~ 11001000 00010111 00011111 11111111 | 2 |
| Otherwise | 3 |
最长前缀匹配
选择 Link Interface 遵循最长前缀匹配原则。
例题:下面转发表
目的地址11001000 00010111 00010110 10100001 和 11001000 00010111 00011000 10101010 分别对应的Link Interface为?
11001000 00010111 00010110 10100001 -> 0
11001000 00010111 00011000 10101010 -> 1(与1和2都匹配,但是与1匹配更长)
2.虚电路和数据报网络选择
Internet:网络核心简单,复杂度在网络边缘
- 计算机数据交换:弹性服务,没有严格时间要求
- 链路类型多:有不同特性,不能统一服务
- “智能”端系统
ATM:复杂度在网络核心
- 电话演变而来
- 人之间的交流:严格的时间限制、可靠性、确定的服务保障
- “笨拙”端系统
4.3 路由器工作原理
1.路由器结构
- 输入端口(Input port)
- 交换结构(Switch fabric)
- 输出端口(Output port)
- 路由选择处理器(Routing processor)
- 上半部分为控制面板:软件、毫秒级
- 下半部分为数据面板:硬件、纳秒级
1.输入端口(Input port)
线路端接(line termination):物理层功能,用来比特的接收
数据链路处理(协议,拆封)(data link processing (protocol, decapsulation)):数据链路层功能,比如以太网
查找、转发、排队(lookup, forwarding, queueing)
- 分散交换:给出数据报目的地,然后根据转发表查找输出端口
- 目标:希望在“line speed”上完成输入端口的处理
- 排队:数据报到达速度大于转发速度

2. 交换结构(Switch fabric)
三种交换结构:共享内存、共享总线、交叉开关矩阵
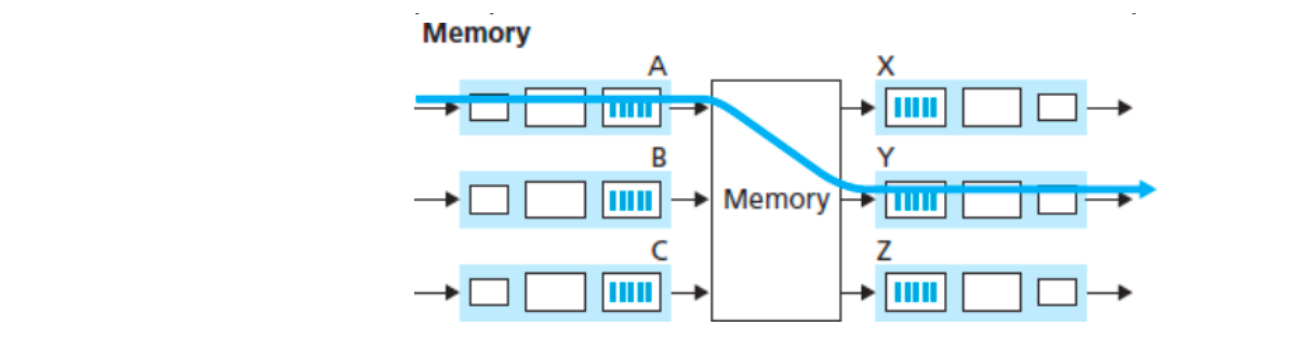
1.共享内存(Switching via memory)
- 初代路由常采用共享内存
- pkt在memory复制
- 速度被内存带宽限制,每个datagram都要经过2个bus
- Cisco Catalyst 8500
2.共享总线(Switching via a bus)
- datagram通过共享的bus从输入端口到输出端口
- 总线冲突(bus contention):交换速度被总线带宽限制
- Cisco 5600

3.交叉开关矩阵(Switching via an interconnection network)
- 客服总线带宽的限制
- 纵横式交换机是一种由2N条总线组成的互联网络,连接N个输入端口和N个输出端口
- 可并行转发多个分组,但如果同输入输出端口,还是必须等待前一个发送了再发下一个
- Cisco 12000

3.输出端口(Output port)
排队(缓存管理)(Queueing(datagram buffer))
- 缓存:当数据报到达快于传输速率,如果缓存不够会导致丢包
- 调度方法:从排队中选择数据报进行传输,例如按时间顺序、按优先级顺序
数据链路处理(协议,封装)(Data link processing(protocol, encapsulation))
线路端接(Line termination)

3.排队
1.输入端口排队
- 当fabric比input port慢时,发生排队
- buffer满时,出现排队延时和丢包
- 队首阻塞(Head-of-the-Line blocking,HOL):队首的datagram会阻塞排在它后面的datagram输入
2.输出端口排队
- 当switch到达比output line快,发生排队
- buffer满时,出现排队延时和丢包
4.4 路由算法(Routing algorithms)
1. 概述
路由协议
目标:从源到目的找到一条最好的路径
- 一般,最好路径是最小代价路径
- 但也可以有其他定义

- 路由 -> 节点
- 物理链路 -> 边
- 链路代价:可以是延时、花费或拥塞等级等等
路由图表示:
- 路由器集合:
- 链路集合:
- 路径cost:
路由算法:找到cost最小路径
路由算法分类
全局/分散信息
- 全局:知道所有路由信息
- 分散:只知道邻居路由的信息,需要进行迭代查询
静态/动态
- 静态:需要手动配置,路由变化慢
- 动态:路由变化快,周期更新
2.LS算法:路由选择算法(Link state alorithm)
1.Dijkstra算法
- 基于全局信息的算法
- 计算从源到所有其他节点的最小cost
- 迭代:经过k次迭代可知到k个目的的路径cost
算法步骤如下: G={V,E}
- 初始时令 S={V0},T=V-S={其余顶点},T中顶点对应的距离值 若存在,d(V0,Vi)为弧上的权值 若不存在,d(V0,Vi)为∞
- 从T中选取一个与S中顶点有关联边且权值最小的顶点W,加入到S中
- 对其余T中顶点的距离值进行修改:若加进W作中间顶点,从V0到Vi的距离值缩短,则修改此距离值 重复上述步骤2、3,直到S中包含峙所有顶点,即W=Vi为止


算法复杂度
假如有n个节点,
- 一般的Dijkstra算法需要
- 通过算法优化,可将复杂度降为
Dijkstra算法存在振荡问题。
2.广播路由(Broadcast routing)
通过广播路由得到路由的实时情况。完成广播通信的最直接方式是由发送节点向每个目的地分别发送分组的拷贝。
洪泛(Flooding):从源发送pkt到所有其他的节点
无限制洪泛会引起广播风暴(Broadcast storm),导致广播路由耗光了所有的流量。
受控洪泛(Controlled flooding):解决广播风暴问题
序号控制洪泛(Sequence-number-controlled flooding)
源节点将其地址(或其他的唯一标识符)以及广播序号放人广播分组,再向它的所有邻居发送该分组。每个节点维护它已经收到的、复制的和转发的源地址和每个广播分组的序号列表。当一个节点接收到一个广播分组时,它首先检查该分组是否在该列表中。如果在,丢弃该分组;如果不在,复制该分组并向该节点的所有邻居转发。
反向路径广播(Reverse Path Broadcasting,RPB)
RPB 的基本思想是当一台路由器接收到具有给定源地址的广播分组时, 仅当该分组到达的链路正好是位于它自己到其源的最短单播路径上,它才向其所有出链路 (除了它接收分组的那个)传输分组。否则,该路由器丢弃入分组。

生成树广播(Spanning-tree broadcast):消除了冗余广播pkt,而且能够被任何节点用于开始广播分组
- 在生成树上广播pkt,这样就不再会有圈了

LS算法
LS算法 = 广播路由 + Dijkstra算法
- 广播路由:每个节点都要广播链接状态pkt给每个其他节点,从而每个节点都获得相同完整的网络信息
- Dijkstra算法:计算源到每个节点的最小cost路径
- 如果有link cost变化,则重新进行上述操作
DV算法:距离向量算法(Distance vector algorithm)
DV算法为基于分散信息、动态的路由算法。
Bellman-Ford公式
定义
Bellman-Ford方程:
例题:通过
对于节点x
- 知道邻居节点v的
- 维持邻居的距离向量
- 知道邻居节点v的
DV算法
- 每个节点定期发送它的 DV estimate 给邻居
- 当一个节点x收到邻居发来的新的 DV estimate 时,它会根据 B-F公式 更新自己的 DV estimate
- 多次更新后,DV estimate 会收敛于真实的最小cost dx(y)dx(y)
迭代、异步: 每个本地迭代产生于:
- 本地链接cost改变
- 邻居发来新的 DV estimate
分布:
- 每个节点只会在它的DV改变的时候才会通知邻居
- 邻居如果改变再通知邻居

好事传得快,坏事传得慢
- “好事”(cost变小):更新完成快
- “坏事”(cost变大):更新完成慢,造成无限问题
如何解决无限问题?
如果要节点最小cost路由要绕路(即不是邻居),则标为∞∞
LS算法和DV算法对比
| LS | DV | |
|---|---|---|
| 信息复杂度(Message complexity) | O(nE)O(nE)(n个节点,E条链路) | 只在邻居之间交换 |
| 收敛速度(Speed of convergence) | O(n2)O(n2),可优化到O(nlogn)O(nlogn) | 速度会变化 |
| 强健性(Robustness) | 有一定强健性,每个节点都有自己的表 | 强健性低,节点依赖于邻居 |
层次路由(Hierarchical Routing)
之前讨论的路由都是理想化的:所有路由器都相同,网络是“扁平”的。而实际,并不存在这样的理想路由。
大规模
- 无法存储所有目的的转发表
- 路由交换流量大,导致淹没链路
管理自治
- 因特网是网中网
- 每个网络管理都希望控制所在网络的路由
聚集路由成自治系统(autonomous system,AS)
AS内的路由
(intra_AS routing)
- 在一个AS间的路由
- 在一个AS的所有路由器运行同一个区域内协议
- 不同AS的路由器运行不同区域的协议
- 网管路由器:位于AS边缘,与其他AS的路由器有链接
AS间的路由
(inter_AS routing)
- 在不同AS间的路由
- 网管参与区域间的路由
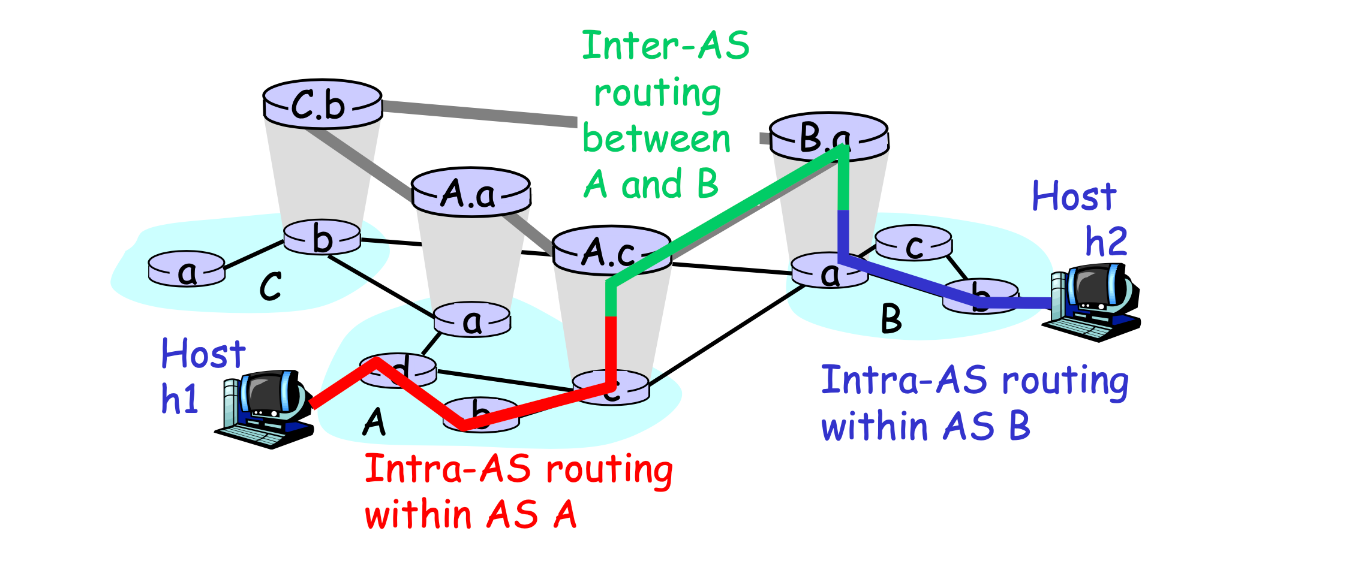
AS分类
- Stub AS:末端AS,用于小企业
- Multihomed AS:多出口AS,用于大企业,外部不能通过它传输
- Transit AS:中转AS,网络提供商,用于传输
4.5因特网中的路由选择
内部网关协议(Interior Gateway Protocols,IGP)是AS内的路由。
常用的IGP有:
- RIP:路由信息协议,Routing Information Protocol
- OSPF:开放最短路径,Open Shortest Path First
- IGRP:Interior Gateway Routing Protocol
RIP:路由信息协议(Routing Information Protocol)
DV算法
cost:跳数
最大15跳,16跳视为∞∞。设置最大跳数以防止无穷计数问题,但这也限制了只能用于小网络,大网络很容易超最大跳数。
每30s通过发送通告的方式更新DV,通告最多路由到25个目的
如果超过180s每收到通告,则这个邻居/链路宣告死亡
通过该邻居的路由失效
发送新通告给邻居
如果邻居的转发表变化,它也会发送新的通告
链接失败的信息会快速迭代完成
- 采用毒性逆转防止循环
- 将16跳设置为∞∞
RIP运行在应用层(路由器实际可能存在应用层,只是不对用户开放)
通告用 UDP pkt 周期性发送

OSPF:开放最短路径(Open Shortest Path First)
OSPF概述
对公众开放
使用
LS算法
- 需要发送LS pkt
- 每个节点采用拓扑结构
- 路由采用 Dijkstra 算法
OSPF通告每个邻居路由器携带一个条目
通告通过洪泛散布到整个AS
- OSPF消息直接分装在IP数据报上
OSPF优点
- 安全:所有OSPF消息都要认证,防止恶意侵入
- 多条相同cost的路径:当到达某目的的多条路径具有相同的cost时,OSPF允许使用多条路径。即可以分流。
- 每条链路,给不同的数据类型不同的cost度量
- 对单播和多播(MOSPF)路由的支持:对单播进行扩展,以便提供给多播使用
- 在大域中用分层OSPF
分层OSPF
两层结构:
局部区域(local area)和主干(backbone)
- LS通告只在区域内
- 每个节点知道该区域的拓扑结构,对于其他区域只知道到那个区域的方向(最短路径)
区域边界路由器(area border router):负责为流向该区域以外的分组提供路由选择。汇拢该区域的节点距离信息,通告给其他的区域边界路由器
主干路由器(backbone router):在主干内运行OSPF路由
网关路由器(boundary router):与其他AS连接

IGRP(Interior Gateway Routing Protocol)
- 最初是CISCO私有的,后来开放了,RIP的后继者
- DV算法
- cost:时延、带宽、可靠性、负荷等等
- 利用TCP来交换路由更新
- 利用扩散更新算法(Diffusing Update Algorithm,DUAL)来防止循环
BGP:边界网管协议(Border Gateway Protocol)
BGP概述
采用 Path Vector protocol
- 与DV协议相似
- 每个边界网关向邻居(对等方)广播到达目的地的整个路径(即 AS的序列)
- eBGP:外部BGP,跨越两个AS对话。从相邻的AS获取子网可达性信息。
- iBGP:内部BGP,同一个AS中的两台路由器之间的BGP对话。将可达性信息传播到所有内部AS路由器。
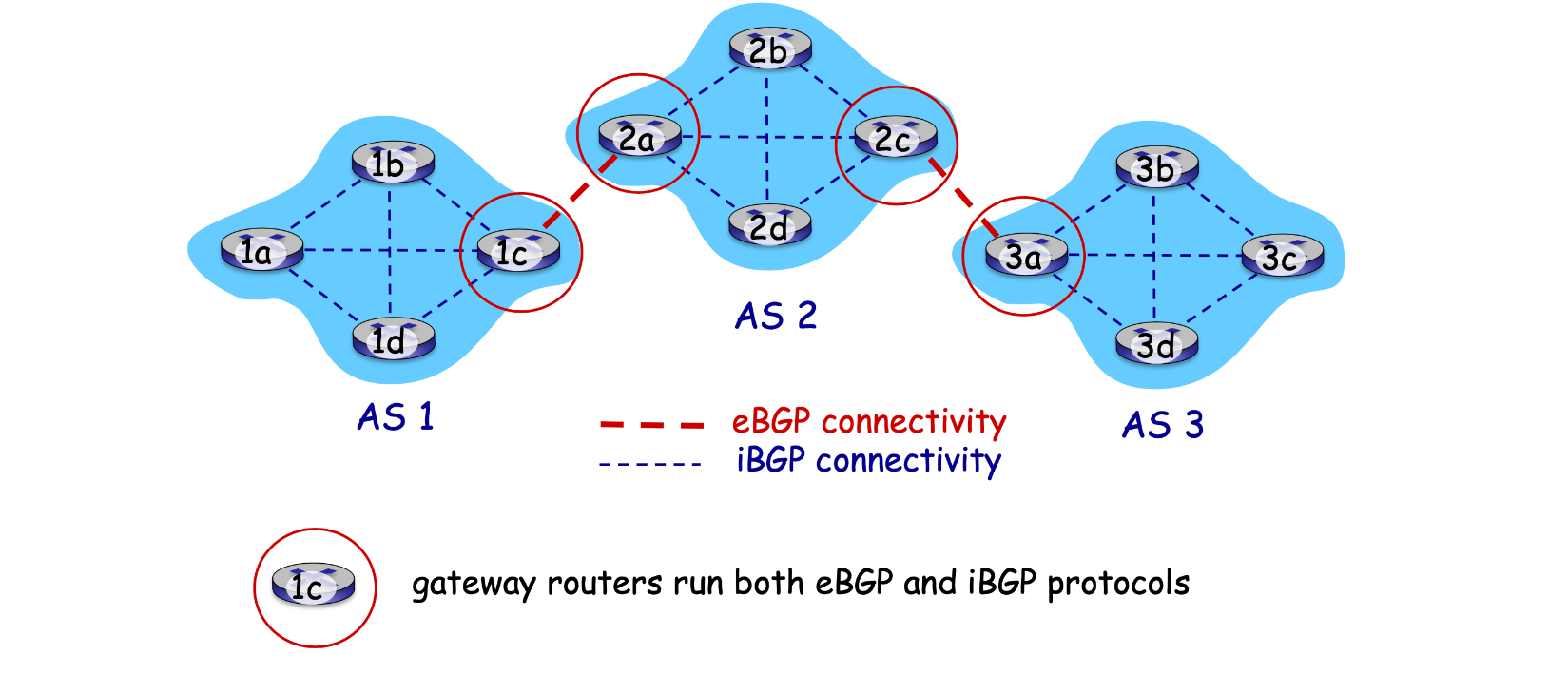
BGP会话:两BGP路由器通过半永久的TCP连接来交换消息
- 将路径通告到不同的目标网络前缀(BGP是“路径向量”协议)
如果一个AS向另一个AS通告了某个路由器,则承诺了可以路由到该路由器
路径属性和BGP路由
通告前缀(advertised prefix)包括BGP属性
- prefix + attributes = “route”
两个重要attributes
- AS-PATH:路径中的AS的列表
- NEXT-HOP:以AS-PATH开头的路由器接口的IP地址
基于policy的路由
- 网关接收路由广告使用导入policy接受/拒绝路径(例如,从不通过AS Y路由)
- AS policy还确定是否向其他相邻AS通告路径
BGP消息
使用TCP交换BGP消息
BGP消息:
- OPEN:打开TCP连接,认证sender
- UPDATE:通告新路径(删除旧路径)
- KEEP ALIVE:在没有UPDATE的情况下,保持连接活跃;ACK OPEN请求
- NOTIFICATION:报告以前的msg中的错误;也用于关闭连接
BGP路由选择
路由器可能知道到达同一个前缀的多条路由。BGP以下优先级选择路由:
- 本地偏好值:由政策决定
- 最短 AS-PATH:通过的AS最少
- 最近 NEXT-HOP 路由器:最近的下一跳路由器
- 其他标准
假设:网关X 将其路径发送到 网关W
W 可以选择/不选 X所提供的路径
- 根据cost,policy(eg.不通过竞争对手的AS进行路由),防止环路 的原因选择/不选
如果W选择X通告的路径
X可以通过advertisement来控制传入流量:
- eg.不希望将流量路由到Z -> 不通告任何路由到Z
BGP路由策略

A,B,C是ISP(网络服务提供商)
W,X,Y是客户
X是 Multihomed AS,连接了两个ISP,也可以称为 dual-homed,一般是大型公司。X可以不允许 B -> X -> C 这条路由,则X不通告B有路由到C
A 通告 B 路径 AW
B 通告 X 路径 BAW
是否 B 通告 C 路径 BAW ?
- 不会,C不是B的客户,B希望强迫C走AW,B只想从客户发送/接收路由
Inra-/Inter-AS 的区别
规模:分层可以节省表格大小,减小更新的流量。
| Intra-AS | Inter-AS | |
|---|---|---|
| Policy | 一个管理员,不需要policy决策 | 管理员想要控制路由,需要有policy |
| 性能 | 关注性能 | 比起性能更关注policy |
4.6 IP:Internet Protocol
IPv4数据报结构

版本(Version, 4bit) 对于IPv4,字段的值是4。
首部长度(Header Length, IHL, 4bit) 首部长度说明首部有多少32位字(4字节)。一般为5,相当于5*4=20字节。
服务类别(Type Of Service,8bit)
报文长度(Length, 16bit) IP首部+数据部分的总长度
标识(Identification, 16bit) 用于在IP层对数据报进行分片的时候,标识数据包。
标志(Flags,3bit)
这个3位字段用于控制和识别分片,它们是:
- 位0:保留,必须为0;
- 位1:禁止分片(Don’t Fragment,DF),当DF=0时才允许分片;
- 位2:更多分片(More Fragment,MF),MF=1代表后面还有分片,MF=0 代表已经是最后一个分片。 如果DF标志被设置为1,但路由要求必须分片报文,此报文会被丢弃。这个标志可被用于发往没有能力组装分片的主机。 当一个报文被分片,除了最后一片外的所有分片都设置MF为1。最后一个片段具有非零片段偏移字段,将其与未分片数据包区分开,未分片的偏移字段为0。
分片偏移 (Fragment Offset, 13bit) 这个13位字段指明了每个分片相对于原始报文开头的偏移量,以8字节作单位。
存活时间(Time To Live,TTL, 8bit) 本数据报的TTL.
协议 (Protocol, 8bit) 1—-icmp, 2—-igmp, 6—-tcp, 17—-udp, 89—-ospf
首部检验和 (Header Checksum, 16bit) IP首部的校验和
源IP地址(Source IP, 32bit)
目的IP地址(Destination IP, 32bit)
IPv4数据报分片
网络链路有MTU(最大传送单元)— 最大可传输的链路的帧
- 不同的链路类型有不同的MTU
如果IP数据报 > MTU ,则分片,到目的地后再重组
IP头部字段用来标记

IP数据报分片示例

本来要发送 4000 byte 的数据报(head部分 + data部分)
链路的 MTU = 1500 bytes
需要将数据分为3片来发送
length:片长度,包括了 20 bytes IP首部部分,最大为MTU- length为1500的数据报,实际包含 1500−20=1480 bytes1500−20=1480 bytes 的data部分
- 最后一片的length为 (4000−20)−1480×2+20=1040(4000−20)−1480×2+20=1040
fragflag:3 bits- 第二个bit为 DF(Don’t Flag):为0则该数据报分片,为1则不分片
- 第三个bit为 MF:为0则后面没有片了,为1则后面还有片
- 前两片为 1(001),表示该IP数据报分片,且后面还有片
- 最后一片为 0(000),表示该IP数据报分片,后面没片(即最后一片)
offset:data部分偏移量,以 8 bytes 为单位,只计算data部分- 第一片的offset为 0
- 第二片的offset为 1480 bytes/8 bytes=1851480 bytes/8 bytes=185
IPv4编址
概述
IP地址:32位、主机和路由器接口的ID
接口
(interface):主机/路由器 和 物理链接 之间的连接
- 路由器一般有多个接口
- 主机一般有1到2个接口
每个接口都有一个对应的IP地址

接口连接方式
- 通过路由器连接
- 有线以太网通过以太网交换机连接
- 无线网络通过WiFi基站连接
子网(Subnet)
IP地址
- 网络部分 —— 高位
- 主机部分 —— 低位
子网
- 子网部分相同
- 可以不通过路由器到达彼此
把路由器去掉,剩下的每个区域都是一个子网。

上图中有6个子网。
分类编制(Classful Addressing)
A类
- 网络部分前1位 ——
0 - 网络部分 8 bits,主机部分 24 bits
- IP地址范围:
1.0.0.0~127.255.255.255
- 网络部分前1位 ——
B类
- 网络部分前2位 ——
10 - 网络部分 16 bits,主机部分 16 bits
- IP地址范围:
128.0.0.0~191.255.255.255
- 网络部分前2位 ——
C类
- 网络部分前3位 ——
110 - 网络部分 24 bits,主机部分 8 bits
- IP地址范围:
192.0.0.0~223.255.255.255
- 网络部分前3位 ——
D类
- 前4位 ——
1110 - 用于多播地址
- 前4位 ——
E类
- 前4位 ——
1111 - 被留作将来使用
- 前4位 ——

子网掩码(subnet mask)
- IP地址采用点分十进制:例如
192.32.216.9 - 分类编制导致了地址资源的浪费
- 子网和子网掩码:可以减小地址资源的浪费

200.23.16.64/27中的27为 网络部分+子网部分 的位数
子网掩码
- 网络部分+子网部分 置1
- 主机部分 置0
子网的网络ID
- 网络部分+子网部分 不变
- 主机部分 置0
CIDR:无类的域间路由(Classless InterDomain Routing)
- IP分为两个部分 —— 子网部分 + 主机部分
- 子网部分可以是任意长度
- 地址格式:
a.b.c.d / x,其中x是子网部分位数 - 网络部分称为前缀(prefix)
如何获取IP地址
主机如何获取IP地址
主机获取IP地址:
- 硬编码:自己设置静态的IP设置
- DHCP:动态主机配置(Dynamic Host Configuration Protocol) 当主机连接网络时,允许主机从网络服务器动态获取IP地址。
DHCP
- 即插即用
- 可以更新IP
- 地址重用:主机的IP只有在上线时才固定,下线即释放
- 支持移动用户
当一台主机加入网络时,从子网中的DHCP服务器获取IP地址。

网络如何获取IP地址
从ISP处获取分配的IP地址。

ISP如何获取IP地址
ISP从ICANN组织获取IP地址
ICANN:Internet Corporation for Assigned Names and Numbers
- 分配地址
- 管理DNS
- 分配域名、解决争议
NAT:网络地址转换(Network Address Translation)
从这个本地网络出去的报文都有着:相同的源IP+不同的端口号
对于外界网络来说,这个本地网络都是一个IP
- 本地网络有内部地址,改变该内部地址不需要通知外部网络
- 改变ISP不需要改变本地网络的内部地址
- 内部地址在外部不可见(保障安全性)
实现方式
发送出去的报文:(源IP(内部的IP),端口号)—> (NAT IP(NAT统一的IP),新端口号)
- 外部发来的报文的目的地址填写:(NAT IP(NAT统一的IP),新端口号)
NAT转换表:记住(源IP(内部的IP),端口号)<—> (NAT IP(NAT统一的IP),新端口号)的转换对
收到的报文:根据NAT转换表,(NAT IP(NAT统一的IP),新端口号)—> (源IP(内部的IP),端口号)

外部不知道内部的情况,所以外部不能发起通信
预留给内部的IP地址:
10.0.0.0~10.255.255.255(A类)176.16.0.0~172.31.255.255(B类)192.168.0.0~192.168.255.255(C类)
可以有16bit的主机地址位(
10.0.0.0~10.255.255.255),一个NAT支持内部60000+的连接NAT存在争议
- 路由器本来是在第3层,但NAT修改了端口号,而端口号包含在TCP/UDP的段结构里,即改了第4层的内容
- 违反了端到端
- 所以用IPv6来解决地址短缺
ICMP:因特网控制消息协议(Internet Control Message Protocol)
ICMP
主机、路由器、网关来交流网络层信息
- 报错:到达不了主机、网络、端口、协议等等
- 用于探测:echo request/reply(使用ping)
IP的一部分,但体系结构在IP之上:ICMP消息搭载在IP数据报上
ICMP消息:type,code,引发错误的IP数据报首部和前8个字节
| Type | Code | description | 描述 |
|---|---|---|---|
| 0 | 0 | echo reply (ping) | echo响应 (被程序ping使用) |
| 3 | 0 | dest. network unreachable | 目标网络不可达 |
| 3 | 1 | dest host unreachable | 目标主机不可达 |
| 3 | 2 | dest protocol unreachable | 目标协议不可达 |
| 3 | 3 | dest port unreachable | 目标端口不可达 |
| 3 | 6 | dest network unknown | 未知的目标网络 |
| 3 | 7 | dest host unknown | 未知的目标主机 |
| 4 | 0 | source quench (congestion control - not used) | 源端关闭(拥塞控制) |
| 8 | 0 | echo request (ping) | Echo请求 |
| 9 | 0 | route advertisement | 路由通告 |
| 10 | 0 | router discovery | 路由器的发现/选择/请求 |
| 11 | 0 | TTL expired | TTL 超时 |
| 12 | 0 | bad IP header | IP 报首部参数错误 |
ICMP是管控制的IP的“兄弟”
ICMP被IP使用,同时作为网络层协议使用IP
ping、traceroute、path MTU discovery 都使用到了ICMP
ping:使用 ICMP Echo request/repley msgs
path MTU discovery
- 发送一个大的IP数据报,该数据报的 don’t fragment 置 1(即不分片)
- 减小数据报大小,直至成功(成功标志:没有接收到返回的ICMP消息)
Traceroute
Traceroute程序:跟踪从一台主机到其他主机之间的路由,用ICMP报文实现。
源发送一系列 UDP报文段 到目的
- 第一个数据报 TTL=1,第二个数据报 TTL=2,以此类推
- 使用不常见的端口号
当第n个数据报到达第n台主机时
- 这个第n个数据报TTL刚好过期
- 路由器丢弃该数据报
- 路由器发送一个ICMP告警报文(type 11,code 0)给源
- 该ICMP告警报文包括第n台路由器名字及其IP
当该ICMP报文返回到源主机,源主机计算RTT(往返时延),得到第n台路由器名字及其IP
标准的Traceroute程序用相同的TTL发送3个一组的分组,输出对每个TTL提供3个结果
停止条件步骤
- UDP数据报到达目的主机
- 目的主机返回 ICMP端口不可到达报文(type 3,code 3)
- 源主机接收到该ICMP报文,则停止
在Mac上可在app“系统信息”中的窗口->网络实用工具中使用Ping、Traceroute等工具。
IPv6
动机
- 初动机:解决32位IP地址空间分配完的问题
- 更快处理/转发的头部格式
- 头部支持QoS
IPv6数据报格式
- 固定长度的头部:40 byte (IPv4头部长度不固定)
- 不允许分片
IPv6数据报结构

版本(Version, 4 bit) 对于IPv6,字段的值是6(0110)。
流量类型(Traffic class,8 bit)
用来标识对应IPv6的通信流类别,类似于IPv4中的ToS。
流标签(Flow label,20 bit)
用来标记报文的数据流类型,以便在网络层区分不同的报文。
有效载荷长度(Payload length,16 bit)
给出了IPv6数据报中跟在定长的40 byte数据报头部后面的字节数量。
下一个头部(Next Header,8 bit)
该字段标识数据报中的内容(数据字段)需要交付给哪个协议(如TCP或UDP)。无扩展的头部,Next Header指向TCP/UDP;有扩展的头部,Next Header指向的下一个头部比如路由选择。与IPv4头部 协议(Protocol)字段相同。

跳段数限制(Hop limit,8 bit)
生存时间,相当于IPv4中的TTL。转发数据报的每台路由器讲对该字段内容 -1,如果跳转限制计数到0时,则丢弃该数据报
源IP地址(Source Address,128 bit)
目的IP地址(Destination Address,128 bit)
数据(Data)
IPv6相较于IPv4的部分改变
去除Checksum:加快了转发速度
Options:依旧允许可选项,但是不放在头部,而是放在 Next Header 指出的位置上
ICMPv6
:ICMP的IPv6版本
- 增加新的 type:比如“Packet Too Big”
- 包含多播组管理
IPv6地址
三种类型:单播(unicast)、多播(multicast)、任意播(anycast)
冒号划分的十六进制(128 bit)
eg.
68E6:8C64:FFFF:FFFF:0:1180:960A:FFFF0的压缩
用双冒号
::表示一组0或多组连续的0,但只能出现一次。FF05:0:0:0:0:0:0:B3=FF05::B30:0:0:0:0:0:128.10.2.1=::128.10.2.1(IPv4和IPv6兼容的IP)12AB:0:0:CD30:0:0:0:0=12AB::CD30:0:0:0:0=12AB:0:0:CD30::(如果出现两个多个0,随意压一个都行)
单播(Unicast address)
单播的地址格式(一共 128 bit):
全球路由前缀(Global routing prefix,48 bit)
前3位为
001,分配给公司和组织。子网ID(Subnet ID,16 bit)
如果是小公司,只需要1个子网的话,全设为0
接口ID(Interface ID,64 bit)
基于 EUI-64
IPv4到IPv6的迁移
现在的网络既有IPv4,也有IPv6。世界上的所有网从IPv4到IPv6需要很长的转换时间。
两种IPv4到IPv6的迁移
- 双栈(Dual Stack):一些路由器可以兼容IPv4和IPv6
- 隧道(Tunneling):当IPv6穿过IPv4的路由器上时,将IPv6作为载荷承载在IPv4上
双栈(Dual Stack)
- 早期的设计
- 一些路由器有双栈(IPv4 & IPv6),可以翻译这两种格式

隧道(Tunneling)
当IPv6穿过IPv4的路由器上时,将IPv6作为载荷承载在IPv4上。就是像一个连接两个IPv6路由器的IPv4隧道

第五章 链路层(Link Layer)
5.1概述
保证帧流的透明传输
链路层服务:
成帧(Framing)、接入链路(link access)
- 将来自上级的数据报分装成帧,加上header、trailer
- 完成共享媒体的信道连接
- 物理地址,用来 indentify 源/目的,在帧头中
可靠交付(Reliable delivery)
- 可靠数据传输协议(rdt)
- 在可靠的传输情况下很少应用,一般应用在高错误概率的链路传输中
流量控制(Flow Control)
- 协调发送方和接收方
差错检测(Error Detection)
差错纠正(Error Correction)
5.2成帧(Framing)
主要考虑帧的界定,即如何将前一帧和后一帧分开。
1.字符计数法(Character count method)
在每帧的前面添加 Counting header(本帧长度)

2. 基于字符的首尾界定法(First and tail bound method based on character)
设定两个ASCII——SOH、EOT,SOH为标注开始的字符,EOT为标注结尾的字符。

如果中间的数据部分也有SOH或EOT,则加入转义字符 EOT 标识。类似于C语言中的\的作用。

3. 基于bit的首尾界定法(First and tail bound method based on bit)
与基于字符的首尾界定法的思路相似,但开始和结束的标志为01111110

为防止中间的数据部分也有01111110导致提前结束
- 发送方:每5个
1后插入一个0 - 接收方:每5个
1后删除一个0

4.物理层违逆码法(Pysical layer coding violation method)
比如在曼切斯特编码中,如果
- 高低表示
1 - 低高表示
0 - 那么 低低/高高 就可以用来表示开始和结束
违逆码只能应用在物理层,因为违逆码无法储存。
5.3差错检测(Error Detection)
通过增加冗余位(EDC)来检测差错。
差错检测不是100%可靠的。
可能会漏掉一些错误,但是概率很小
更大的EDC检错能力更强

1. 奇偶校验(Parity Checking)
单个奇偶校验位(Single Bit Parity)
分为奇校验和偶校验,EDC长度为1 bit。
如发送一个长为dd bit 的信息时,加EDC一共
- 偶校验中,则EDC需使这
1(即如果发送的信息有偶数个1,则EDC为0;奇数个1,则EDC为1) - 奇校验中,则EDC需使这
1(即如果发送的信息有偶数个1,则EDC为1;奇数个1,则EDC为0)
下图采用偶校验,信息D中共有9个
1,所以偶校验位为1。
奇偶校验只能检测出奇数个错误的情况。但由于现在传输的准确率很高,就算出错,大概率也就出 1 bit 的错误,所以使用简单的奇偶校验也能检测出大部分错误。
- 偶校验中,则EDC需使这
二维奇偶校验(two-dimensional parity)
将DD中的dd bit 划分成ii行、jj列,计算每行和每列的奇偶校验值,产生

二维奇偶校验不仅可以检测错误,还可以利用奇偶校验差错的行和列的索引找出错误的比特位,进行纠错。
2. CRC校验(Cyclic Redundancy Check)
CRC(Cyclic Redundancy Check),循环冗余检测。
思路:发送信息DD,设置一个生成多项式,利用冗余位RR,将D+RD+R凑成生成多项式的整数倍,在接收方如果无法整除,则出差错。

生成多项式GG和CRC比特位数
设置一个
比如下面,三次项和常数项系数为11,则二进制数GG的第四位和第一位为11
生成多项式GG为r+1r+1 bit,则CRC冗余位为rr bit。如此才能保证能把D+RD+R凑成GG的整数。
计算CRC冗余位RR
增加RR的目的是实现:
先将信息DD乘以2r2r,即左移rr bit,后面补
0。再将移位后的D×2rD×2r除GG,但是中间步骤不用减,而用异或。比如信息DD为
101110,生成多项式0,得101110000,再除以G=1001
得到的余数
011则为CRC冗余位RR。发送方发送信息DD和冗余位RR的拼接,即
101110011。接收方检错
接收方收到发送方发来的
101110011后,将其除以生成多项式GG1001。如果整除则未检测到差错,否则检测到差错。
5.4多路访问链路和协议(Multiple Access Links and Protocols)
链路的两种类型:
点对点链路(point-to-point link)
由链路一端的单个发送方和链路另一端的单个接收方组成。
广播链路(broadcast link)
多个发送方和接收方,单一的、共享的信道。
多路访问协议(Multiple access protocol),规范结点在共享的广播信道上的传输行为。
多路访问协议分类:
信道划分协议
(channel partitioning protocol)
- 静态
- 将信道平分给各节点
- 优点:公平、相互不干扰
- 缺点:闲置占有带宽
随机接入协议
(random access protocol)
- 动态
- 独占信道
- 允许冲突,并能从冲突中恢复
轮流协议
(taking-turns protocol)
- 上两种的结合
- 紧密协调共享访问以避免冲突
多路访问协议的目标:高效、公平、简单、分布式
1.信道划分协议(Channel Partitioning protocols)
1. 时分多路复用(TDMA)
TDM将时间划分为时间帧(frame),并进一步划分每个时间帧为NN个时隙(slot),链路中的每条连接专用一个时隙。
详见 时分多路复用(TDM)。
2. 频分多路复用(FDMA)
链路中的每条连接专用一个频段。
详见 时分多路复用(FDM) 。
3. 码分多址(CDMA)
详见 码分多路复用(Code division multiplexing,CDM) 。

2.随机接入协议(Random Access protocols)
结点传输pkt时,占有信道全部带宽,结点间无优先级
存在多个传输结点 => 碰撞
随机接入协议明确了:
- 如何检测碰撞
- 如何从碰撞中恢复
常用的随机接入协议
- ALOHA
- Slotted ALOHA
- CSMA 和 CSMA/CD
1.纯ALOHA(Pure ALOHA)
非时隙、简单、完全分散
最早的ALOHA,目前已经不再使用
帧长一定 => 帧传输时间一定
当一帧首次到达(从网络层传下来),结点立即将该帧完整传输进广播信道
如果发送碰撞,则该结点
- 有pp的概率,将立即以重传该帧
- 有1−p的概率,等待一个帧传输时间,再以pp的概率判断是否重传

假设一帧在t0t0处开始传输,则在[t0−1,t0+1][t0−1,t0+1],其他结点如有传输,发生碰撞,则易损时间区长度为2τ2τ(tautau为一帧的传输时间)。
一个结点发送成功,则需要本结点发送、其他结点在[t0−1,t0][t0−1,t0]和[t0,t0+1][t0,t0+1]不发送。一个给定结点成功传送的概率为
则有NN个结点,任意一个结点成功传送的概率为
如此,求得纯ALOHA的最大效率为1/(2e)≈0.18(改变p,使S最大化)。
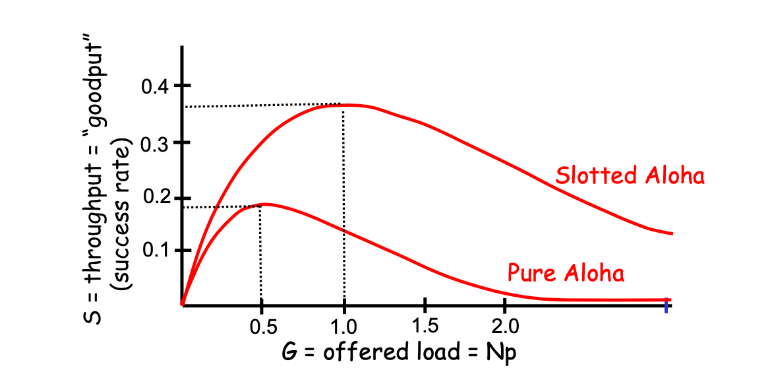
2.时隙ALOHA(Slotted ALOHA)
- 时间被划分成长度相等的时隙(slot)
- 结点只在时隙起点开始传输帧
- 如果碰撞,在下一时隙的开始以p的概率重传,直至成功。

假设一帧在t0处开始传输,则在本时隙中,其他结点如有传输,发生碰撞,则易损时间区长度为τ(ττ为一帧的传输时间)。
一个给定结点成功传送的概率为
如果有NN个活跃结点,任意一个结点成功传送的概率为
如此,求得时隙ALOHA的最大效率为1/e≈0.37(改变pp,使SS最大化)。即在有大量结点有帧要传输时,最多3737的时隙做有用的工作,信道传输速率不是R bps,而是0.37R bps。
时隙ALOHA的最大效率是纯ALOHA的两倍。
3.CSMA:载波侦听多路访问
载波侦听多路访问(CSMA,Carrier Sense Multiple Access),一个结点在传输前先侦听信道。
如果侦听到信道空闲,则传输帧
如果侦听到信道正忙,则推迟传输。再传输方式分为坚持型和非坚持型:
- 坚持型CSMA(Persisitent CSMA):一直坚持监听,直到信道空闲时,立即以概率pp重试(可能导致不稳定)。其中1-坚持型CSMA的p=1,即立即重试。
- 非坚持型CSMA(Non-Persisitent CSMA):不再监听,等待一个随机的时间之后再进行监听。
CSMA依旧会发生碰撞
只要共享信道,那么碰撞就是不可避免的,即使CSMA有侦听。
比如下图中,B结点在t0时传输帧,但是帧的传输是需要一定时间的,这就导致在t1时,D结点侦听判断信道空闲,传输帧。两信号发生碰撞。

如此,整个帧传输时间被浪费了。可以看出,广播信道的端到端信道传播时延(distance and propagation delay)(信号从一个结点到另一个结点的传播时间)在决定性能上起关键作用。
4.CSMA/CD:具有碰撞检测的载波侦听多路访问
碰撞要在短时间内检测出来(最好在一个争用期内)
一旦检测到碰撞立即停止传输,以减少信道的浪费
采样坚持型或非坚持型重传
碰撞检测
- 有线网络检测碰撞比较简单:如阈值法、过零法等等
- 无线网络检测碰撞比较困难
如下图,当B结点和D结点检测到碰撞时,立即停止继续发送。

争用期:以太网的端到端往返时间2τ
A结点给B结点发送帧流,最坏情况就是在即将发送到B结点时,发生碰撞,返回碰撞信息,最大用时即为2τ。
最短帧:最短帧长度为2τR(R为信道速率)
和上述同样的最坏情况中,从A结点发送帧,到碰撞信号返回到A结点花费2τ2τ的时间,在此期间A结点不能停止帧的发送,所以最短帧的长度为2τR。
如此可以最大利用网络效率,而且不会产生二义型。如果发送完了这个帧,没有发生碰撞,则发生成功。

CSMA/CD 效率
CSMA/CD 效率:当有大量的活跃结点,且每个结点有大量的帧要发送时,帧在信道中无碰撞地传输的那部分时间在长期运行时间中所占的份额。
其中,tprop为两结点之间的最大传播时间;
ttrans为传输一个最大长度的帧的时间。
效率趋近1,则需
- tprop -> 0
- 或,ttrans -> ∞
CSMA/CD 比 ALOHA 简单、便宜、分布式。
3.轮流协议(Taking-Turns protocol)
1.轮询协议(Polling protocol)
有一个主结点
主结点以循环的方式轮询每个结点
主结点先向一个结点发送报文,告诉能够传输的帧的最多的数量,这个结点传输完帧后,主机点再发给下一个结点报文,循环轮询。

缺点:
- 主结点需先给结点发送报文,增加开销
- 轮询时延,不及时
- 如果主结点出故障,则整个网络无法工作
2.令牌传递协议(Token-Passing protocol)
令牌(token)在结点之间以某种固定次序进行交换
结点只有在拿到令牌时,才能发送帧
受控的,不会发生碰撞

缺点:
- 令牌开销
- 时延
- 令牌环会故障
5.4局域网技术
1.局域网模型
局域网模型中,数据链路层分为LLC子层和MAC子层。
- 逻辑链路控制层(Logical Link Control,LLC):为上层(网络层)提供连接环境
- 媒体接入层(Media Access Control,MAC):为下层(物理层)提供媒体接入
2.局域网地址和ARP
1.MAC 地址
可以叫MAC 地址、LAN地址、物理地址
用于从一个接口到另一个物理连接的接口(同一网络)获取数据报
MAC地址长度:4848 bit / 66 byte
与硬件有关,一个网卡(适配器)对应一个MAC地址
例如:
1A-2F-BB-76-09-AD与局域网相连的每个接口都有唯一的MAC地址

MAC地址由IEEE分配
IEEE给公司固定MAC地址的前2424 bit,后2424 bit由公司保证每个适配器MAC地址的唯一性
IP地址和MAC地址的关系:IP地址就像是一个邮件地址,解决在哪上网的问题;MAC地址像身份证,解决谁在上网的问题
- IP地址层次结构,主机移动,主机的IP地址也改变
- MAC地址扁平寻址结构,不会因为位置改变MAC地址
2.ARP:地址解析协议
ARP(Address Resolution Protocol),地址解析协议
局域网中的每个IP结点(主机、路由器)都有ARP表
ARP表:局域网结点的IP地址和MAC地址的对应关系
- 每行的结构:
<IP address; MAC address; TTL> TTL:存活时间,过TTL的时间要丢弃这一行数据

- 每行的结构:
1.同一子网内的地址解析
A想要发送数据报给B,但是B的MAC地址没有记录在A的ARP表中。
A发送一个
广播帧
——查询ARP分组,包含B的IP地址
- 目的MAC地址:
FF-FF-FF-FF-FF-FF - 所有结点都会收到该ARP查询分组
- 目的MAC地址:
B接收到ARP分组,给A回复B的MAC地址
- 给A的MAC地址单播帧——响应APR分组
A在ARP表中缓存IP到MAC地址对,直至超时TTL
ARP即插即用:ARP表自动建立,不需要系统管理员来配置
2.不同子网的地址解析
不同子网的A和B通过路由器R发送数据报,A只知道B的IP地址,不知道B的MAC地址
A创建IP报文(IP地址在整个传输过程中不改变)
- 源IP地址:A的IP
- 目的IP地址:B的IP
A创建数据帧,在IP报文的基础上,加上MAC地址
- 源MAC地址:A的MAC
- 目的MAC地址:路由器R左端的MAC(路由器R左端与A在一个子网中)
帧从A传到路由器R
路由器R接收帧,并从路由器R的数据链路层传到网络层,从数据帧拆成IP数据报
路由器R在IP报文的基础上,加上新的MAC地址段,传到数据链路层
- 源MAC地址:路由器R右端的MAC(路由器R右端与B在一个子网中)
- 目的MAC地址:B的MAC
帧从路由器R传到B,B接收到数据

3.以太网(Enternet)
1.以太网物理拓扑
总线型
早期流行,所有的结点共用一条总线。

星型
以太网现在使用的拓扑结构,中间是交换机,所有结点和交换机的连接是唯一的,不会发生冲突。

2.以太网帧结构

前导码(Preamble,7 byte)
7 bytes 的方波
10101010,用于“唤醒”接收适配器,并将它们的时钟与发送方的时钟同步。帧开始符(Start of Frame Delimiter(SFD),1 byte)
10101011,用来警告接收适配器,要开始了。目的MAC地址(Destination address,6 byte)
目的适配器的MAC地址。
源MAC地址(Source address,6 byte)
源适配器的MAC地址。
类型(Type,2 byte)
上层的协议。比如,IP协议对应
0X0800。数据(Data,46~1500 byte)
IP数据报。
最小长度——46 byte
由2τR2τR决定。IEEE 802.3中,2τ为51.2μs,R=10Mbpss,由此得到最小帧长度64 bytes。再减去18 bytes的其他部分,得到最小数据的长度46 bytes。
详见CSMA-C中的最短帧。
小于最小长度得补充到46 byte。
最大长度——1500 byte
超过最大长度得分片。
帧校验序列(FCS,4 byte)
错误检测机制,比如CRC。
3.以太网技术
- 无连接:不需要握手
- 不可靠:不需要发送ack或nack
- 以太网MAC协议:非时隙、1-坚持、二进制指数退避的CSMA/CD
1.二进制指数退避CSMA/CD算法
xxxxxxxxxx141A: //A事件2sense channel, if idle //如果侦听信道空闲3then {4transmit and monitor the channel; //传输并监听信道(监听是否有其他站点在传输)5if detect another transmission //如果监听到其他站点在传输6then {7abort and send jam signal; //停止并发送jam信号(将冲突信号发送给其他站点)8update # collisions; //更新冲突次数(冲突次数+1)9delay as required by exponential backoff algorithm; //调用二进制指数退避算法来延时10goto A //重新执行A事件11}12else {done with the frame; set collisions to zero} //如果在传输的过程中没监听到其他站点在传输,则完成帧的传输,并将冲突次数清零13}14else {wait until ongoing transmission is over and goto A} //如果侦听信道在忙,则继续侦听,直至信道空闲,再发送(1-坚持);如果是非坚持,则等待一个随机的时间之后再进行监听
Jam Signal:长48 bits48 bits,保证每个其他的发送方意识到冲突
2.二进制指数退避算法(Binary Exponential Backoff Algorithm)
一旦检测到冲突,为降低再冲突的概率,需要等待一个随机时间,二进制指数退避算法即解决时延时间的问题。
时延的时间为端到端的往返时间2τ2τ的整数倍,即
- 初始的冲突次数k=0;
- 每冲突一次,则k=k+1;
- 如果k<10,n从[0,2k)中随机选择一个整数(注意⚠️:右边为开区间),则延时2τ×n的时间;
- 如果k≥10,则n从0,1,2,3,…,1023中随机选择一个,延时2τ×n的时间。(k在10之后就不再增加时延的选择范围,防止延时过长)
3.802.3以太网标准
不同的以太网标准有:
- 相同的MAC协议和帧格式
- 不同的速度:2/Mbps、10 Mbps、100 Mbps等等
- 不同的物理层媒体:光纤、铜线
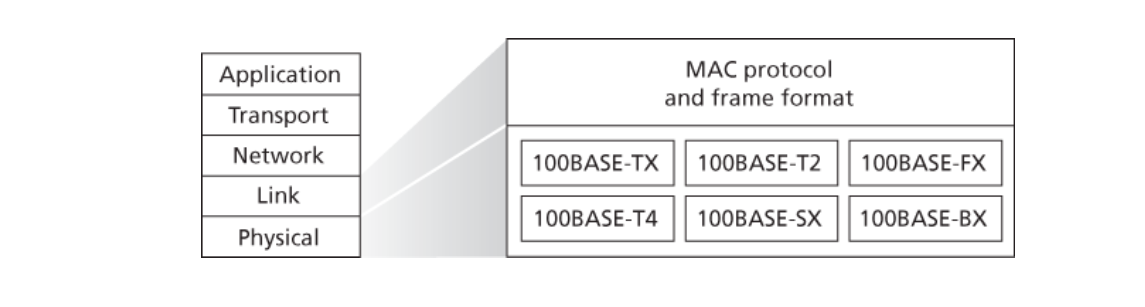
下图为100 Mbps以太网标准,其中100代表$100\ Mbps,TX、T2、T4代表媒体为不同的铜线,FX、SX、BX代表媒体为不同的光纤。
4.交换机(Switch)
1.集线器(Hub)
物理层设备:相当于工作在bit 层的传话筒,将接收到的bit从一个接口传到其他的所有接口
层级结构
每个连接的LAN称为LAN网段
集线器不会隔离冲突域
集线器的优点
- 简单便宜
- 如果一个集线器发生故障,则局域网的其他部分将继续运行
- 扩展节点对之间的最大距离(每个集线器100m)
集线器的缺点
- 未隔离冲突域,导致最大吞吐量没有增加(多层吞吐量与单段吞吐量相同)
- 单独的LAN限制对相同冲突域中的结点数以及允许的总地理覆盖范围进行了限制
- 无法连接不同的以太网类型(例如10BaseT和100baseT)
由于上述缺陷,如今大部分集线器已被交换机取代

2.以太网交换机概述
交换机,也可以叫网桥
链路层设备
存储、转发以太网帧
检查传入的帧的MAC地址,有选择地将帧转发到一个或多个传出链路,使用CSMA / CD访问段
- 收到的帧与发送的结点在同一网段,则丢弃该帧
- 收到的帧的目的MAC地址在转发表里,且与发送的结点不在同一网段,则向目的地址所对应端口转发该帧
- 收到的帧的目的MAC地址不在转发表里,则泛洪
透明:主机不知道交换机的存在
即插即用,自学习(不需要配置交换机)

- 主机有专用的、直接的到交换机的连接
- 交换机缓存pkt
- 每个输入链路都使用以太网协议,但是没有冲突
- 全双工
- 每个链路都是自己的冲突域
- A至A’和B至B’可以同时传输而不会发生冲突
3.交换机自学习
- 每个交换机都有一张交换表作为转发表,交换表的每行数据为
<MAC address, interface, TTL>,即MAC地址、通向该MAC地址的接口、存活时间。 - 交换机表初始为空
- 交换机每接收到一个帧,就记录一条数据(发送结点的数据)
- 过了TTL,则删掉该条数据
4.交换机转发与过滤
xxxxxxxxxx91when frame received at switch: //交换机接收到帧21. record incoming link, MAC address of sending host //在交换表中记录发送方的传入接口、MAC地址32. index switch table using MAC destination address //在交换表中查找目的MAC地址43. if entry found for destination //如果在交换表找到了该目的MAC地址5then {6if destination on segment from which frame arrived then drop frame //如果目的与发送方在同一网段,则丢弃该帧7else forward frame on interface indicated by entry //如果不在同一网段,则转发帧到相应接口8}9else flood //如果在交换表找到不到该目的MAC地址,则泛洪(转发到除发送方所在接口以外的所有接口)
5.交换机 vs 路由器
| 路由器 | 交换机 | |
|---|---|---|
| 存储转发 | 有 | 有 |
| 所在层 | 网络层设备(检查网络层头部) | 链路层设备(检查链路层头部) |
| 转发表 | 使用路由算法,IP地址 | 使用泛洪,自学习,MAC地址 |
5.VLAN:虚拟局域网
交换机以太网存在缺点:缺乏广播隔离,导致易产生广播风暴。
为解决上述问题,采用虚拟局域网VLAN。
VLAN:在单个LAN内,将支持VLAN功能的交换机配置为多个虚拟LAN。
1.基于端口的VLAN
将单个LAN基于端口划分为多个VLAN。
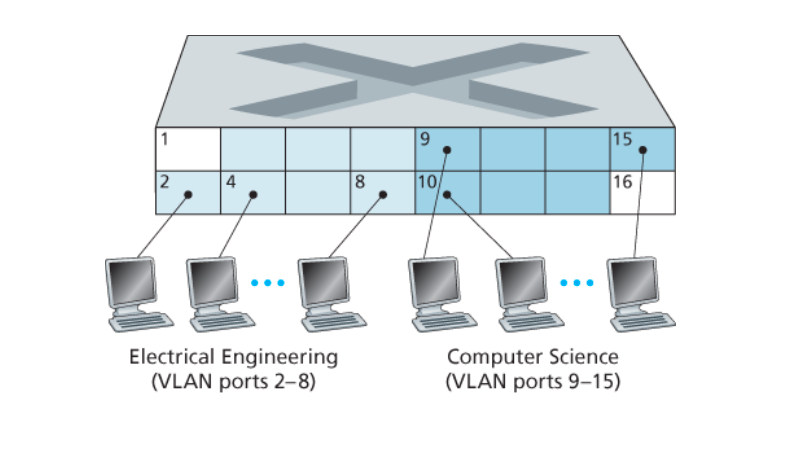
- 流量隔离:帧只能在本VLAN内往返(VLAN相当于一个真实的局域网,将功能限制在链路层,只能传帧)
- VLAN之间的转发:通过路由完成(就像使用单独的交换机一样)
- 动态成员资格:端口可以在VLAN之间动态分配
2.跨多个交换机的VLAN
最早采用实体线相连,后采用中继端口。
中继端口(trunk port):也可以叫共享端口,在多个物理交换机上定义的VLAN之间传送帧。
下图中,a为实体线相连,b为中继端口连。

802.1q:原802.1帧未带有VLAN标识,所以802.1q协议为中继端口之间转发的帧添加/删除了其他报头字段

- 增加了4 byte
- 前2 byte为协议标识
- 后2 byte中,前12 bit为VLAN的ID,后3 bit为优先级
- 由于位数改变,CRC需重算